




Executive summary
The modern enterprise is built upon a cloud foundation. The rapid adoption of software as a service (SaaS) and infrastructure as a service (IaaS) platforms has accelerated business agility, minimized capital expenditures, and fueled unprecedented operational scale.
However, this absolute reliance on cloud-hosted systems has introduced a critical paradox: By shifting core infrastructure outside their physical and administrative boundaries, organizations have created deep, systemic dependencies on external networks and third-party providers.
When these dependencies fail—due to physical fiber cuts, routing misconfigurations, Domain Name System (DNS) failures, or regional outages within major hyperscalers—modern operations come to an immediate halt. For critical industries such as healthcare, defense, manufacturing, utilities, finance, retail, and transportation, a loss of cloud connectivity is not merely an IT inconvenience; it is a threat to human safety, national security, and economic stability.
Business Continuity Planning (BCP) in a cloud-first era requires additional planning. By looking at traditional BCP methodologies, digging into modern edge computing frameworks like AWS Outposts, and demonstrating identity-centric survivability through the offline capabilities of the Okta Local Authentication Service, we show that localized survivability is no longer a luxury. It is a fundamental strategy for the modern enterprise.
How does cloud redefine business continuity planning?
For decades, the standard IT paradigm dictated that resiliency was achieved by duplicating physical infrastructure—building secondary data centers, provisioning redundant power, and utilizing geographic separation. The transition to the cloud shifted this burden to cloud service providers (CSPs). Many business leaders mistakenly assumed that cloud adoption was synonymous with guaranteed availability.
What are the risks of relying solely on cloud infrastructure?
While major cloud and SaaS providers invest billions of dollars in multi-region failover and highly available architectures, they remain vulnerable to single points of failure. A single misconfigured Border Gateway Protocol (BGP) route, a DNS resolution failure, or a cascading API error in a primary hyperscaler region can instantly disconnect thousands of organizations from their critical systems.
This vulnerability isn't entirely digital. A single backhoe operator cutting a subterranean fiber-optic line during routine street repair—or a targeted act of physical sabotage—can instantly sever an enterprise's lifeline to the cloud, rendering otherwise functional remote resources entirely unreachable.
In these moments, the cloud provider may be fully operational internally, but because the enterprise network cannot reach the provider's endpoints, the service is effectively down.
What core security principles apply to resilient network planning?
To address these risks, continuity planning must integrate core principles of information security and disaster recovery:
Mapping what matters: The reality check
Before you can fix anything, you need to know what you're actually protecting. That means identifying the absolute core parts of your business that cannot go down and tracing them back to every single cloud provider or SaaS tool they rely on. If you don't know where your dependencies are, you can't protect them.
The survival equation: Why the math breaks
In the security world, there’s a basic rule for business survival: Your Maximum Tolerable Downtime (MTD)—the absolute limit of how long your business can stay alive while bleeding money—has to be longer than the time it takes to fix the technical issue, known as your Recovery Time Objective (RTO), plus the time it takes to get your data and people back to normal work (WRT):
MTD >= RTO + WRT
Here is the catch with the cloud: If you lose connectivity completely, your RTO stretches out indefinitely because fixing connectivity can be entirely out of your hands. If you don't have an offline alternative, that equation breaks completely, and the business runs out of time.
Graceful degradation: "Island mode"
If an enterprise loses connection to the outside world, it must be able to fail gracefully—becoming an operational "island." The local network must support core, life-sustaining, or revenue-producing tasks at a decreased capacity without relying on external cloud handshakes.
How do cloud disconnects impact critical industries?
Different industries and businesses operate quite differently; however, the need for resilience when using the cloud cuts across many industries. Below is a detailed mapping of how cloud disconnects impact some critical industries, demonstrating where localized operational continuity is mandatory:
How cloud disconnects threaten business continuity
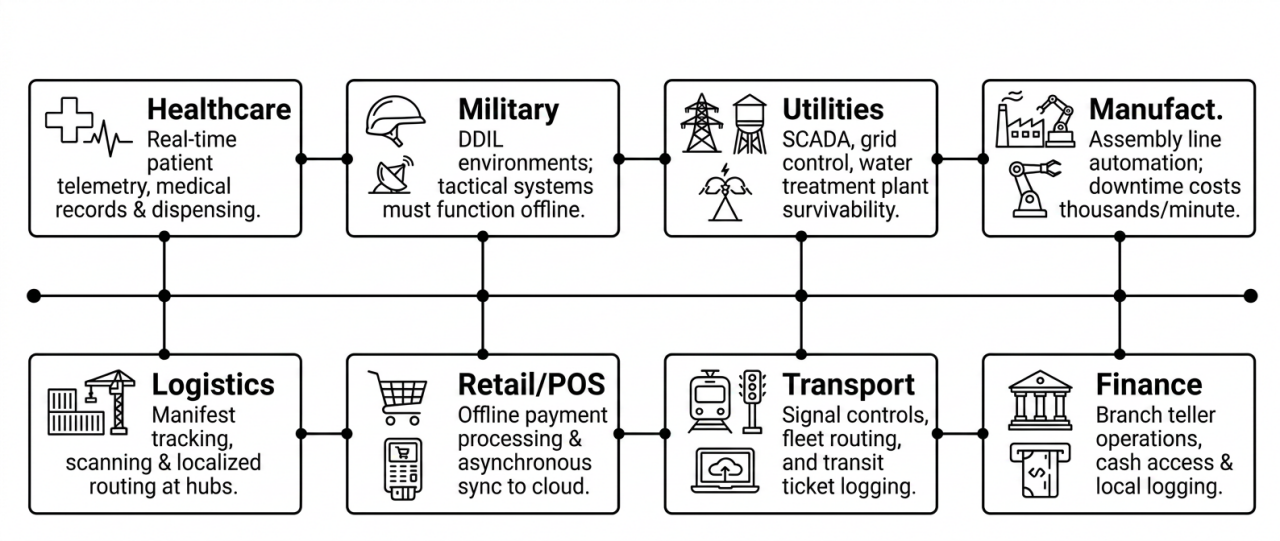 Mapping of critical industry vulnerabilities during outages.
Mapping of critical industry vulnerabilities during outages.
Industry-specific vulnerabilities
Healthcare and clinical operations
In hospitals, immediate access to Electronic Health Records (EHRs), real-time patient telemetry, and automated medication dispensing cabinets are matters of life and death. If the connection to a cloud-hosted EHR is severed, clinicians lose visibility into critical patient histories, allergies, and ongoing treatments. Medication workflows stall, directly compromising patient safety.
Military and tactical defense
Military forces routinely operate in Denied, Degraded, Intermittent, or Limited (DDIL) connectivity environments. Command centers, communication arrays, and tactical logistics systems must function reliably without a persistent uplink to a central cloud. In defense architectures, a hard dependency on external cloud services represents a severe national security vulnerability.
Utilities and critical infrastructure
Power grids, water treatment systems, and energy transmission pipelines rely on Supervisory Control and Data Acquisition (SCADA) systems. These industrial control systems must monitor and adjust physical infrastructure locally. If the cloud-connected monitoring layer drops, the localized systems must maintain a secure, autonomous hold to prevent catastrophic systemic failures.
Manufacturing and industrial automation
Modern smart factories depend on high-speed industrial IoT networks and automated assembly systems. Even a brief network blip can desynchronize robotics, stall production lines, and lead to significant waste. Unplanned downtime in heavy manufacturing costs tens of thousands of dollars per minute, requiring local edge controllers to run without remote handshakes.
Transportation and shipping logistics
Ports, distribution hubs, and global shipping lines cannot afford logistics bottlenecks. If regional cloud services drop, autonomous guided vehicles (AGVs) must continue to navigate safely, manifest scanning must proceed, and container routing systems must queue transactions locally, synchronizing asynchronously when the WAN link recovers.
Why is identity the primary security control plane?
In modern Zero Trust architectures, identity is the primary security control plane. An organization can deploy highly resilient on-premises applications. Still, if those applications rely on an unreachable cloud identity provider (IdP) for user authentication, they are functionally useless in the event of a disconnection.
How standard redirection flows fail during cloud outages
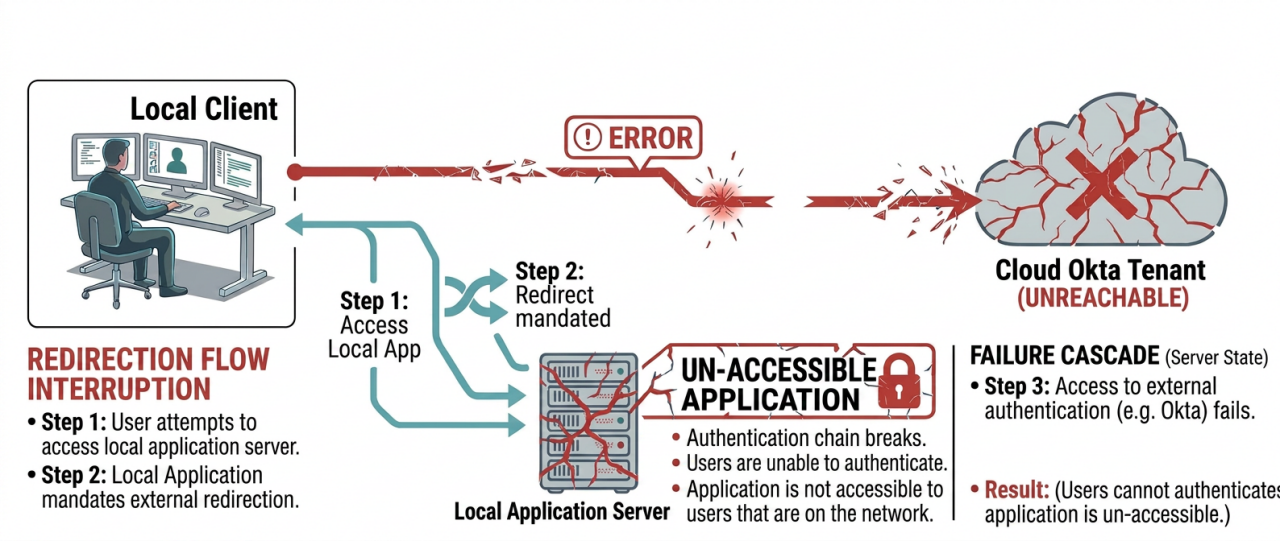 Failure cascade of redirection flows during cloud outages.
Failure cascade of redirection flows during cloud outages.
In a typical cloud-based identity deployment, single sign-on (SSO) using Security Assertion Markup Language (SAML) or OpenID Connect (OIDC) relies on redirecting the user's browser back and forth between the application and Okta. During an internet or SaaS outage:
- The application cannot validate incoming identity assertions.
- The user's browser cannot resolve or reach the cloud authentication endpoints.
- Back-channel token verification checks fail.
To survive, the enterprise network must revert to "island mode"—falling back to local directories and local identity servers that can issue valid tokens natively at the edge. This is important for both traditional web-based applications and agentic AI, where the agent may be on-premises and needs access to on-premises resources.
How does Okta Local Authentication Service maintain uptime?
To resolve the identity survivability bottleneck, Okta has developed the Okta Local Authentication Service, which is built into the Okta Access Gateway (OAG). OAG is a localized gateway appliance deployed on-premises or in a hybrid cloud.
Under this architecture, OAG is not a simple reverse proxy that filters, authenticates, and passes traffic to applications; instead, it functions as the primary IdP for local enterprise applications using SAML and OIDC.
How Okta Access Gateway maintains local authentication during outages
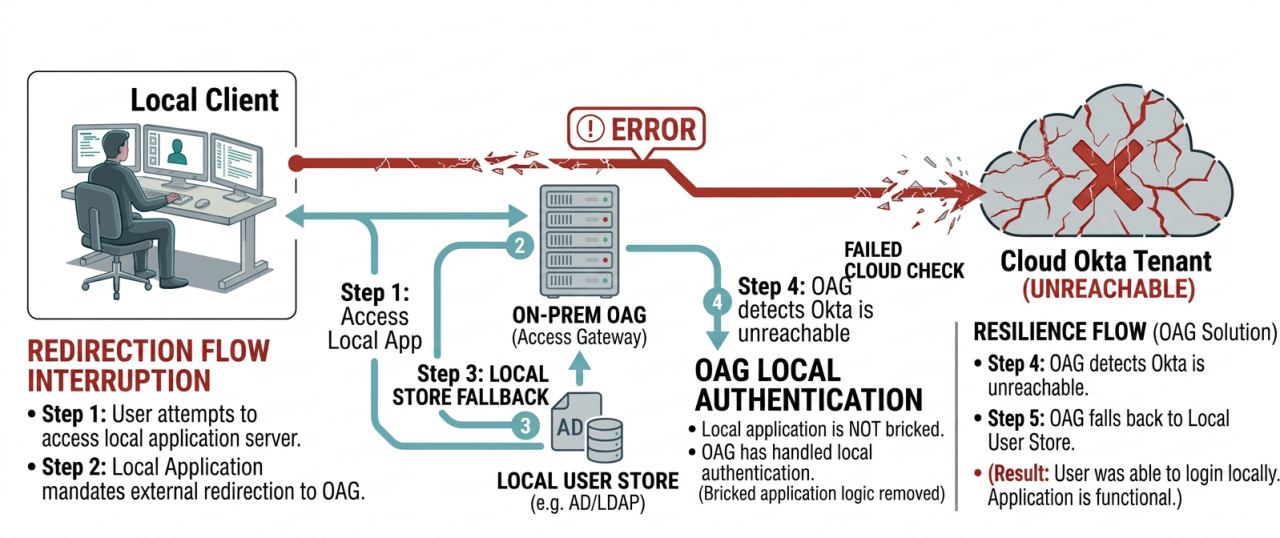 Recovery flow using Okta Access Gateway local authentication.
Recovery flow using Okta Access Gateway local authentication.
The offline transition mechanics
- Continuous health monitoring: OAG continuously monitors the connection status to the upstream Okta Cloud tenant via configurable health-check intervals.
- Outage detection: If the connection failure exceeds the configured fallback threshold, OAG automatically switches the target applications to Disconnected Authentication mode.
- Local credential verification: Instead of redirecting the user to the Okta Cloud tenant, OAG presents a localized, custom disconnected sign-in page. Users enter their credentials, which OAG validates directly against a local directory service such as Active Directory (AD) or Lightweight Directory Access Protocol (LDAP), that is synchronized with the cloud via the Okta AD/LDAP agent.
- Local policy enforcement: OAG evaluates local disconnected authentication policies to ensure only authorized user groups are granted access to critical apps during "break-glass" periods.
- Local token generation: OAG cryptographically signs and issues SAML or OIDC tokens directly from the local appliance to the application, maintaining uninterrupted session access.
What are the limitations of hybrid edge architectures?
To mitigate WAN and cloud-provider outages, achieving true operational resilience requires a multi-layered strategy. While Okta focuses on fortifying the identity control plane, the underlying infrastructure must simultaneously adapt—leading enterprises to increasingly adopt a hybrid edge topology that extends cloud infrastructure directly into local, physical sites.
A primary example of this pattern is AWS Outposts, a fully managed hybrid solution that delivers native AWS services, APIs, and security tools directly to a customer's on-premises facility.
Survivability characteristics of AWS Outposts
Under normal operating conditions, AWS Outposts connects to a parent AWS Region via an active WAN link or AWS Direct Connect. However, when local network connections degrade, Outposts exhibits the following architectural behaviors:
Local execution continuity: Applications already running on the Outpost rack continue to execute locally. They remain reachable by local client devices.
Sub-10 ms latency: Localized systems interact with the Outpost infrastructure with single-digit millisecond latency, bypassing the typical 30 to 100 ms cloud-routing penalty.
Local data traversal: Traffic destined for local databases or on-premises legacy systems routes entirely through the LGW, preventing exposure to WAN vulnerabilities.
Edge limitations
While AWS Outposts represents a step forward for hybrid cloud deployments, it illustrates a fundamental hybrid cloud limitation: It is not designed for permanent, isolated, offline operations.
- Degraded API control plane: In a disconnected state, local administrative actions are severely degraded. API calls to run, start, stop, or terminate instances fail because the control plane resides in the parent AWS Region.
- Log and metric caching limits: CloudWatch metrics and system logs are cached locally on the Outpost rack during an outage. However, this cache is capped at seven days. If connectivity is not restored within this window, critical audit logs, security metrics, and health indicators are permanently lost.
This highlights a key engineering reality: To maintain business continuity, organizations cannot simply rely on hosting infrastructure at the edge. They must also have a resilient, edge-survivable identity control plane to authenticate and authorize users to those local systems.
Okta Access Gateway, running within an AWS Outpost infrastructure, can provide offline authentication and identity at the edge for critical infrastructure in the event of a WAN outage.
How do you configure disconnected authentication policies?
Setting up a resilient identity perimeter requires careful administrative planning. OAG provides granular, localized controls to ensure security policies remain intact even when disconnected from cloud telemetry.
Disconnected authentication policy design
Administrators can define specific rules for offline scenarios. For instance, an organization may want to restrict offline access to highly privileged emergency personnel or ensure a fallback to alternative authenticators.
Configuring disconnected authentication policies in Okta Access Gateway
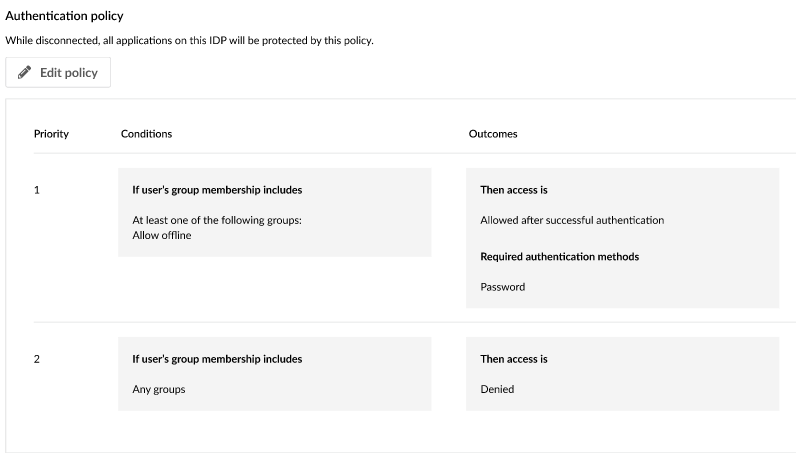 Authentication policy setup for disconnected mode.
Authentication policy setup for disconnected mode.
Custom brand orchestration
During a WAN or cloud outage, user confusion is a major operational risk. OAG allows administrators to customize the disconnected experience to clearly alert users of the altered environment:
- Distinct branding: Maintain custom brand logos and specific operational color palettes.
- Contextual Warnings: Present dedicated user-facing indicators, such as a localized banner: "Disconnected from cloud: options may be limited." This simple addition helps mitigate panic, reduces help-desk ticket volumes, and ensures workers follow defined offline business protocols.
Automatic fallback and recovery thresholds
To prevent "flapping"—where a highly unstable internet connection causes OAG to rapidly cycle between online and offline modes—OAG utilizes dual-threshold state detection:
- Org check interval: The frequency at which OAG checks the availability of the cloud tenant (for example, every 60 seconds).
- Fallback threshold: The number of consecutive failed checks required to trigger disconnected mode (for example, 2 checks).
- Recover threshold: The number of consecutive successful checks required to transition back to online mode (for example, 4 checks). This conservative recovery parameter ensures the WAN link is fully stable before shifting authentication workloads back to the cloud.
Resiliency is a strategy, not a feature
As organizations deepen their cloud integrations, the risk of third-party failures grows exponentially. True operational continuity cannot be achieved by relying solely on service-level agreements (SLAs) or by expecting cloud networks to remain infallible.
To build a world-class, resilient business, leaders must design for failure. Offline access must be approached not as a secondary option, but as an essential architecture strategy. By implementing edge platform models, enforcing strict business impact boundaries, and leveraging technology like the Okta Local Authentication Service, the modern enterprise can confidently cross cloud boundaries—ensuring that if the world goes offline, their business keeps moving forward.
Ready to secure your hybrid cloud boundary?
Don’t wait for the next WAN outage to test your disaster recovery plans. Download our Okta Access Gateway Datasheet to learn how to secure access to your on-premises applications and protect your hybrid cloud without changing your existing code.


