


Okta entwickelt unsere Cloud-Infrastruktur kontinuierlich weiter, um die Bedürfnisse unserer Kunden zu erfüllen. Wir stellen Zuverlässigkeit und Skalierbarkeit in den Mittelpunkt unserer Designentscheidungen für Dienste, die Milliarden von Authentifizierungen pro Monat verarbeiten. Dieser Artikel befasst sich damit, wie ein aktuelles Projekt zur Entfernung eines unserer meistfrequentierten Dienste zu erheblichen betrieblichen und Zuverlässigkeitsverbesserungen geführt hat.
Ein Einblick in Okta’s Edge
In der Vergangenheit empfingen und ermöglichten drei Kerndienste den Großteil des Kundenverkehrs zur Okta Workforce Identity Cloud am Edge: ein Application Load Balancer zum Schutz vor Request Floods, ein Apache-basierter Dienst für die SSL-Terminierung und ein Nginx-basierter Dienst für Routing und Business Logik.
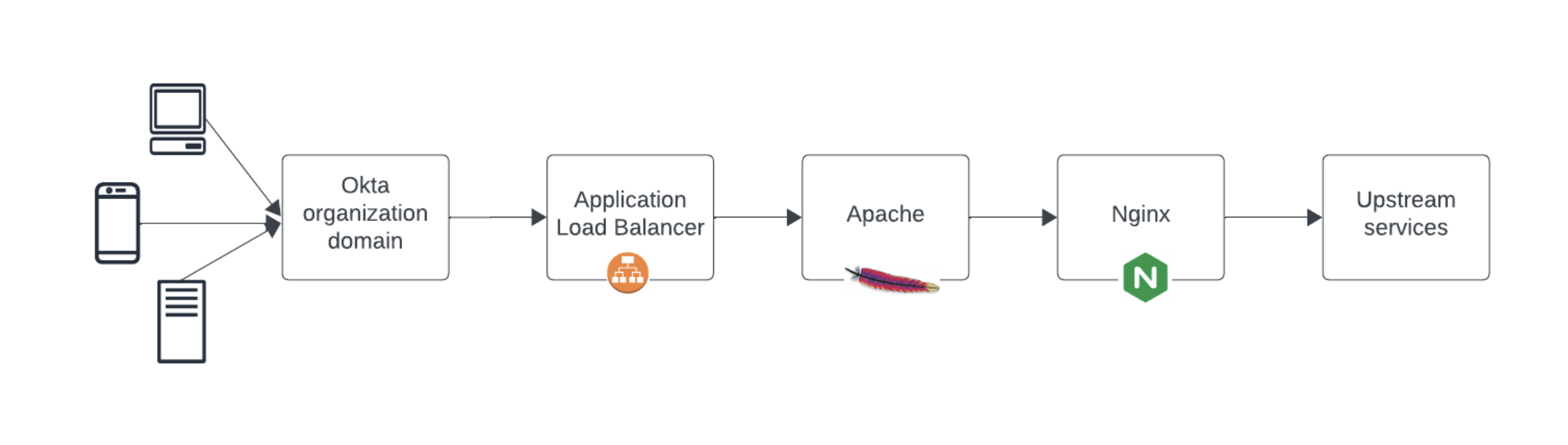
Diese Services werden global eingesetzt und skaliert, um die grossen Datenmengen zu verarbeiten, die Okta täglich verarbeitet. Obwohl diese Services leistungsstark sind, ist die enge Kopplung dieser Services allmählich zu einer operativen Herausforderung geworden. Da wir unsere Infrastruktur stets verbessern wollen, hat sich ein funktionsübergreifendes Team daran gemacht, diese Services neu zu bewerten.
Einer zu viel?
Die Kunden von Okta erwarten einen leistungsstarken und verfügbaren Service, und es ist unerlässlich, dass wir diese Erwartungen erfüllen. Obwohl wir routinemässig unzählige Login-Abläufe verarbeiten, lädt die Öffentlichkeit des Internets zu Unerwartetem ein. Ob vom Kunden initiiert oder anderweitig, Okta erhält zeitweise grosse Traffic-Zuwächse in kurzer Zeit.
Bei der genauen Untersuchung der von uns betriebenen Dienste stellten wir fest, dass der Per-Thread-Flaschenhals von Apache unsere Fähigkeit einschränkte, große Verkehrsaufkommen ohne Auswirkungen zu bewältigen, und beschlossen, diesen Dienst vollständig von unserem Edge zu entfernen. Dadurch würde die Event-Driven-Architektur von Nginx in unserem Stack als besseres Mittel zur Bewältigung unvorhersehbarer Verkehrsmuster vorangetrieben.
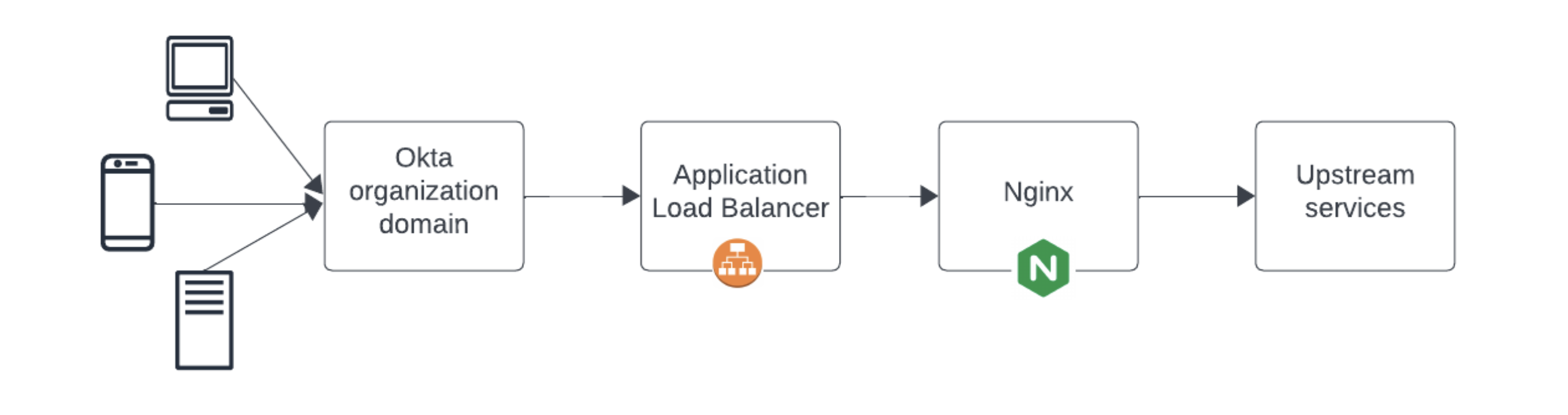
Mit der erhöhten Zuverlässigkeit als wichtigstem Motivationsfaktor würde die Möglichkeit, mehrere hundert Apache-Server zu beenden, zu einer deutlichen Reduzierung des operativen Aufwands führen. Zwischen der Verbesserung der Servicezuverlässigkeit, der Reduzierung unseres Volumens an Systemprotokollaggregation, der Beseitigung von Betriebsaufwand und Kosteneinsparungen würden wir von der Stilllegung unseres Apache-Service erheblich profitieren.
Unser Team entwickelte eine robuste Choreografie, um den Datenverkehr vom Apache-Dienst weg und direkt zu Nginx zu verlagern, sodass wir schnell Probleme beheben konnten, die in Testumgebungen aufgedeckt wurden, bevor wir diese Änderung schrittweise auf unsere globalen Produktionsumgebungen anwendeten.
Im Test
Der Apache-Service von Okta führt eine einfache Java-Anwendung mit benutzerdefinierten Konfigurationen aus, um eingehende Anfragen zu verarbeiten, bevor sie an unseren Nginx-Service weitergeleitet werden. Bei der Entfernung von Apache mussten wir sicherstellen, dass alle vom Service bereitgestellten Funktionen in Nginx neu erstellt wurden. Durch synthetische Tests identifizierte unser Team schnell mehrere Muster eingehender Anfragen, die nach dem Entfernen des Apache-Service nicht mehr ordnungsgemäss verarbeitet wurden.
Das „Doppel-Slash“-Problem
Da Apache einst als erste Anwendung diente, die Kundenverkehr empfing, enthielt er im Laufe der Jahre entwickelte Logiken, um fehlerhafte Anfragen zu identifizieren und ordnungsgemäss darauf zu reagieren. Als die Edge-Infrastruktur von Okta im Laufe der Jahre ausgereifter wurde, wurde diese Funktionalität grösstenteils früher im Stack verschoben. Ein Problem bei der Entfernung von Apache wurde jedoch schnell erkannt – wir waren nicht mehr in der Lage, Anfragen, die // enthielten, ordnungsgemäss zu verarbeiten.
In Testumgebungen ohne den Apache-Dienst gab Nginx falsche Statuscodes für jede Anfrage zurück, die // enthielt. Als konstruiertes Beispiel verhielten sich API-Aufrufe für /api/v1/users weiterhin wie erwartet, aber bei Aufrufen von //api/v1/users wurde beobachtet, dass sie HTTP-Antworten mit Client-Fehlern zurückgeben.
Unser Apache-Dienst verarbeitete diese Anfragen mit einer einfachen Rewrite-Regel, aber Nginx gab Fehlercodes für Anfragen ohne die Rewrite zurück, also mussten wir eine neue Rewrite-Regel einführen, um diese Funktionalität wiederherzustellen.
Unter Beachtung von RFC 3986 wäre dies unsere erste Berührung mit Hyrum's Law.
Das „Query String“-Problem
Mit einer robusten Suite synthetischer Tests zur Validierung der Behebung des „Doppel-Slash“-Problems begannen wir mit der schrittweisen Ausgliederung der Apache-Dienste in unsere Staging-Umgebungen. Als die Menge des ohne Apache verarbeiteten Traffics allmählich zunahm, stellten wir erneut fest, dass Nginx falsche Antwortcodes für bestimmte Anfragen zurückgab, die zuvor von Apache ohne Probleme verarbeitet wurden.
Wie zuvor haben wir einen Fall aufgedeckt, in dem Apache zuvor fehlerhafte Anfragen in ein Format umgeschrieben hat, das Nginx verarbeiten konnte. Im Gegensatz zu RFC 1738hat Apache codierte Abfragestrings in decodierte Werte umgeschrieben. Zum Beispiel wurden Anfragen an /api/v1/users%3Flimit=1 decodiert und als /api/v1/users ?limit=1 an Nginx weitergeleitet. Ohne Apache im Anfragepfad konnte Nginx codierte Abfragestrings nicht verarbeiten und gab eine Fehlermeldung an den Client zurück, der die Anfrage ursprünglich gesendet hatte. Um dies zu beheben, wurde eine zusätzliche Rewrite-Regel in unserer Nginx-Konfiguration eingeführt, und wir konnten mit der Ausgliederung fortfahren.
Mehrere Iterationen später
Die Entfernung eines so prominenten Dienstes erwies sich als keine leichte Aufgabe, wurde aber letztendlich ohne nachhaltige Auswirkungen auf die Kunden erreicht. Diese Bemühungen wurden im Laufe der Zeit mehrfach wiederholt, aber der Fokus auf das Ergebnis blieb derselbe:
- Beseitigung eines Performance-Engpasses
- Verbesserung der Servicezuverlässigkeit
- Reduzierung des Betriebsaufwands
Nachdem diese Bemühungen in allen Umgebungen abgeschlossen wurden, sind die Vorteile schnell erkennbar geworden und das Team plant bereits unsere nächsten Verbesserungen.
Haben Sie Fragen zu diesem Blogbeitrag? Kontaktieren Sie uns unter eng_blogs@okta.com.
Entdecken Sie weitere aufschlussreiche Engineering-Blogs von Okta, um Ihr Wissen zu erweitern.
Sind Sie bereit, unserem leidenschaftlichen Team aussergewöhnlicher Ingenieure beizutreten? Besuchen Sie unsere Karriereseite.
Erschließen Sie das Potenzial eines modernen und anspruchsvollen Identitätsmanagements für Ihr Unternehmen. Kontakt Vertrieb für weitere Informationen.


