



Von Anfang an war es die Vision von Okta, jedem die sichere Nutzung von Technologie zu ermöglichen. Mit dem Aufkommen von Technologien wie KIumfasst diese Vision nun auch die Nutzung Ihres bevorzugten KI-Modells für Ihre Daten mithilfe von Retrieval-Augmented Generation (RAG) und semantischer Suche.
Viele Unternehmen verwenden Active Directory (AD) als ihr Identity Directory. Seit Jahrzehnten werden Benutzer und ihre Gruppenzugehörigkeiten Ad-hoc ohne Governance verwaltet, was zu einer großen Anzahl von Gruppen führt, die nicht verwendet werden, über übermäßige Standing-Privilegien verfügen und keinen Einblick in die Mitgliedschaft der Gruppen haben.
Bislang mussten AD-Administratoren Benutzer anhand ähnlicher Rollen Gruppen zuordnen und anschließend weitere Gruppenmitgliedschaften auf der Grundlage einmaliger Anfragen ohne jegliche Governance hinzufügen. Im Wesentlichen handelt es sich bei diesen Gruppenmitgliedschaften um Cluster von Benutzern mit ähnlichen Attributen, wie z. B. Jobcode, Titel, Abteilung oder Standort. Allerdings werden Sie auch Ausreißer finden, die einmalige Aufträge widerspiegeln. Dieser manuelle und fehleranfällige Prozess eignet sich hervorragend für die Automatisierung und hilft AD-Administratoren vor allem dabei, Vertrauen in die Sicherheit und Governance ihrer Mitgliedschaftskonfigurationen zu gewährleisten.
Gruppendaten mit Retrieval Augmented generativer KI zusammenfassen
Die Verwendung eines RAG-KI-Ansatzes zur Zusammenfassung von Gruppendaten und zur Erstellung von Gruppenbeschreibungen ist eine innovative Anwendung der KI-Technologie zur Lösung dieser Legacy-Herausforderung. Mit den Okta Identity Governance-Funktionen können Teams Zertifizierungskampagnen für AD-Gruppen rationalisieren und den Birthright-Zugriff automatisieren, wodurch Unternehmen ihre Anwendungszugriffe modernisieren und sichern können.
Ein moderner, KI-basierter Ansatz zur Automatisierung des Birthright-Zugriffs kann auf elegante Weise wie folgt realisiert werden:
- Erstellen Sie Dokumentation mit RAG KI und semantischer Suche: Zwei Phasen kommen ins Spiel: das Erstellen und Optimieren des Modells und das Verwenden des Modells zum Generieren von Daten. Dies ist die wichtigste Erkenntnis im Folgenden.
- Starten Sie Okta Identity Governance- Nutzerkampagnen mit Managerzertifizierungen, um unnötige Gruppenmitgliedschaften zu entfernen. Der Manager nutzt die von der KI generierte Dokumentation als Leitfaden, um Gruppenmitgliedschaften zu genehmigen oder zu widerrufen.
- Automatisieren Sie den grundlegenden Zugriff mit den Funktionen von Okta Identity Governance: Entitlement Management, Lifecycle Management und Workflows.
Erste Schritte
Um zu beginnen, muss ein Datensatz mit relevanten Benutzer- und Gruppenattributen erstellt werden. Okta Workflows hilft dabei, eine einfache CSV-Datei mit den Identity-Daten zu erstellen. Der nächste Schritt ist das Aufteilen der generierten Daten in Chunks. Die Chunk-Größe ist ein Hyperparameter des Modells, der optimiert werden kann, und unterschiedliche Chunking-Verfahren führen zu unterschiedlichen Ergebnissen.
Ein Embedding ist ein Vektor oder eine Liste von Gleitkommazahlen. Der Abstand zwischen zwei Vektoren misst ihre Verwandtschaft. Kleine Abstände spiegeln eine hohe Verwandtschaft wider und große Abstände eine geringe Verwandtschaft. Um ein Embedding mit OpenAI zu erhalten, senden Sie jeden Chunk an den OpenAI Embeddings API-Endpoint mit dem Namen des Embedding-Modells (z. B. text-embedding-3-small). Das gewählte Embedding-Modell ist ein Hyperparameter des optimierbaren Modells. Zum Zeitpunkt des Verfassens dieses Artikels sind text-embedding-3-small und text-embedding-3-large die neuesten und leistungsstärksten Embedding-Modelle von OpenAI, die mit niedrigeren Kosten, höherer mehrsprachiger Leistung und neuen Parametern zur Steuerung der Gesamtgröße verfügbar sind.
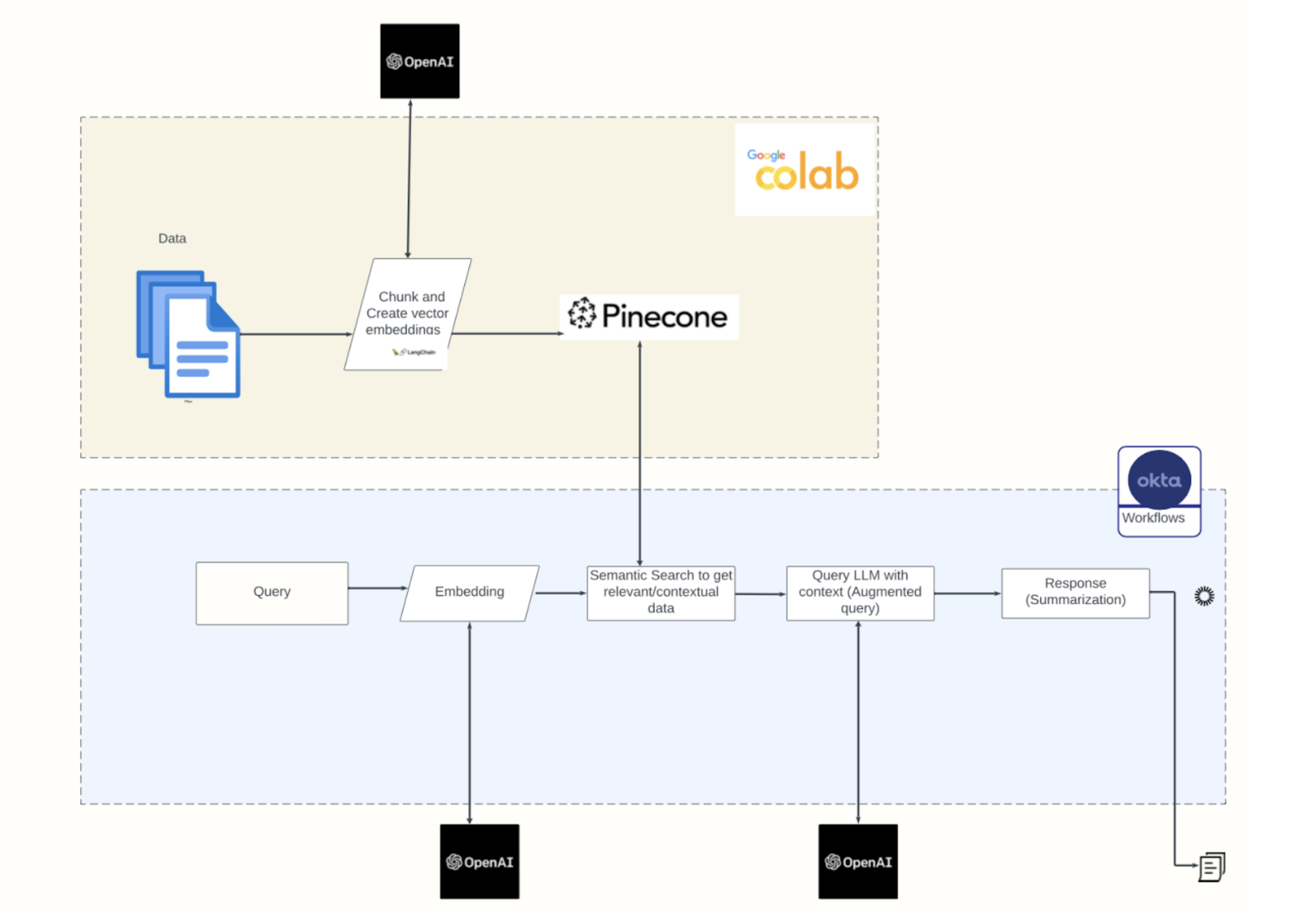
Die nächste „Ausführungs“-Phase zum Generieren von Dokumentation für jede Gruppe verwendet Okta Workflows, um alle Gruppen zu durchlaufen. Im ersten Schritt wird für jede Gruppe eine Anfrage an den OpenAI Embeddings API-Endpoint gestellt, um eine Liste von Vektoren zu generieren, mit dem sofort einsatzbereiten Open AI-Connector.
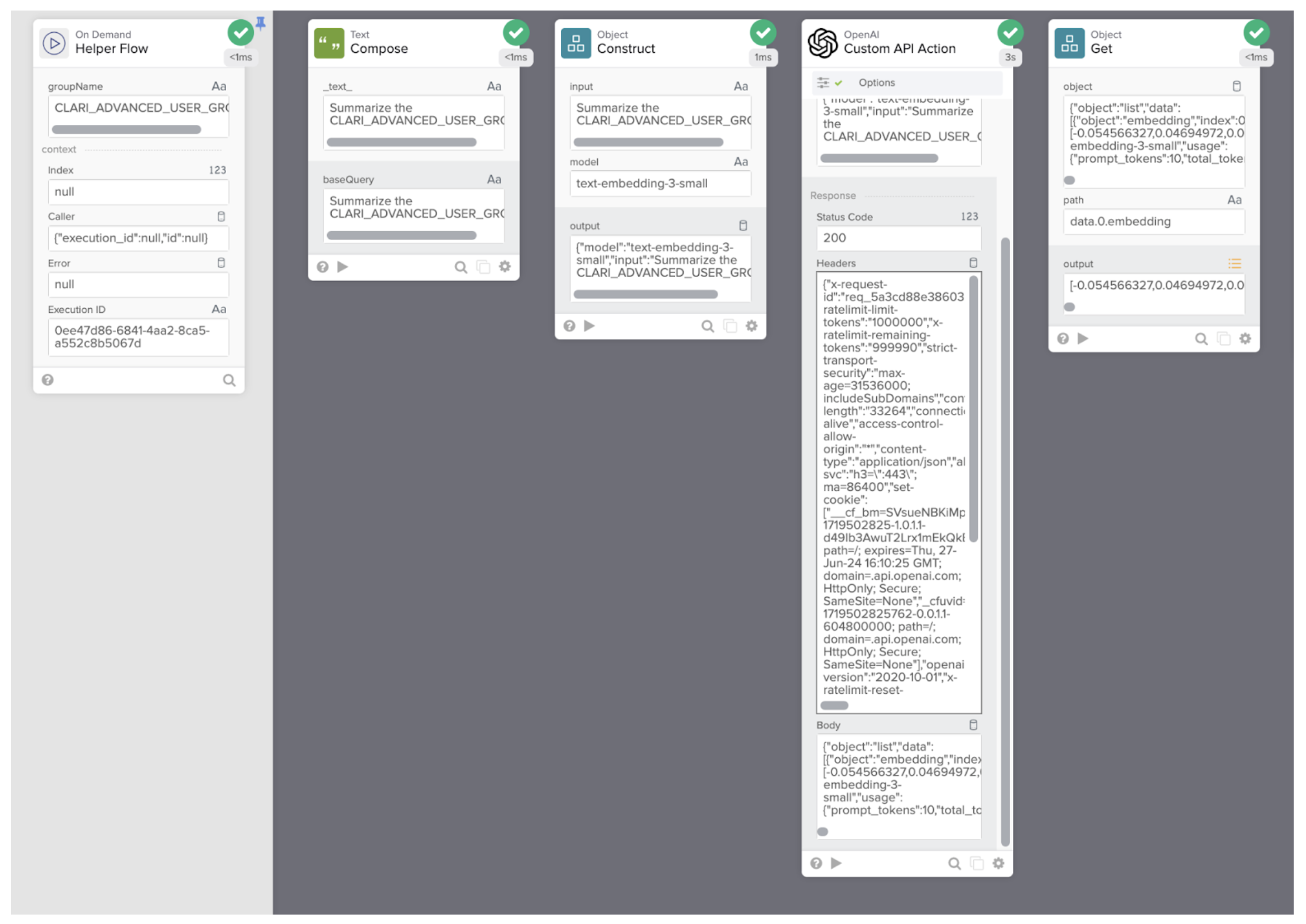
Der nächste Schritt ist das Abrufen der Top-Übereinstimmungen aus einer semantischen Vektordatenbank-Suche.

Mit dem Komfort des vorgefertigten OpenAI Connector gleicht der letzte Schritt nahtlos Ergebnisse aus der Vektordatenbank mit einer zusammengefassten Beschreibung mithilfe der OpenAI Chat Completion API ab.

Die generierte Dokumentation fasst die wichtigsten Informationen über die Benutzer zusammen, die Mitglieder der Gruppe sind, und liefert Zertifizierern wertvolle Informationen, um eine Genehmigungs-/Widerrufsentscheidung zu treffen.
Traditionell waren Unternehmen für die Analyse auf Governance-Anbieter angewiesen, was ihre Fähigkeit einschränkte, die zugrunde liegenden mathematischen Modelle an ihre spezifischen Bedürfnisse anzupassen. Der innovative Ansatz von Okta mit Workflows und Open AI revolutioniert diesen Prozess, indem er es Kunden ermöglicht, KI zu nutzen und die LLMs- und Vektordatenbank-Technologie auszuwählen, die ihren Anforderungen am besten entsprechen.
Diese Flexibilität ermöglicht es Unternehmen, ihre RAG KI-Modelle zu optimieren, um tiefe Einblicke und Datenbereinigung innerhalb von Active Directory zu erhalten. Darüber hinaus automatisieren die fortschrittlichen Governance-Funktionen von Okta den angeborenen Zugriff, was die Zugriffsverwaltung erheblich rationalisiert und die Gesamteffizienz steigert.
Für eine detaillierte Demo und weitere Informationen sehen Sie sich unser Video an: Build a Retrieval-Augmented Generation (RAG) KI Ablauf with Okta Workflows | Online Meetup.


