Adapt to the Cloud Operating Model Part 1: Velocity as the Business Driver

Every company is becoming a technology company. You’ve heard that before. We’ve said that before. The glaring truth behind this statement is that technology is the only way to remain competitive in today’s fast-paced landscape. For some organizations, this means embracing technology; for others, this means leading with it. Either way, the primary way to be a technology company is to deliver software—as famously stated by Marc Andreesen nearly a decade ago, Software is Eating the World.
Software delivery has undergone its own transformation in recent years with the rise of cloud computing. What was once multi-year, waterfall projects to develop and package software for major releases is now a continuous, agile stream of updates. Similarly, what was once fixed data centers of static servers is now dynamic cloud environments of elastic resources across IaaS providers such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
The underlying theme behind software delivery and infrastructure provisioning in the cloud is speed. Competitive pressures and growth both demand it. Businesses must deliver continuous innovation to their customers, which means that developers must deliver continuous innovation back to the business—all in the form of software.
In this virtuous cycle, velocity at scale emerges as the primary business and technical driver, with DevOps programs as the agent of change and method of achievement. Every company is trying to do more with less, which means streamlining as much digital innovation and process improvement as possible. As a result, IT and Security teams are increasingly becoming business enablers. Want to be a hero at your company? Embrace this change. Want to be a leader at your company? Empower your teams.
What is the Cloud Operating Model?
To understand our new paradigm, let’s first look at the traditional operating model. Prior to the advent of the cloud, companies would spend large amounts of capital expenditures on data center space. These environments were fixed, generally sized up for peak traffic on the year. The servers in these data centers were meant to live for years, with one-time configurations and infrequent updates. Any changes to these environments would have to go through a very long, manual, and painful process.
The cloud changed all of this. Companies can now consume a wide array of compute, storage, and networking resources on-demand as pay-as-you-go operating expenses. The environments are dynamic, with elastic resources spinning up and down, adapting to usage patterns in real-time. The resources are immutable, and only meant to last for weeks, days, hours, or even minutes. Environments are configured via automation tools and workflows, with any changes propagating across the fleet near instantly.
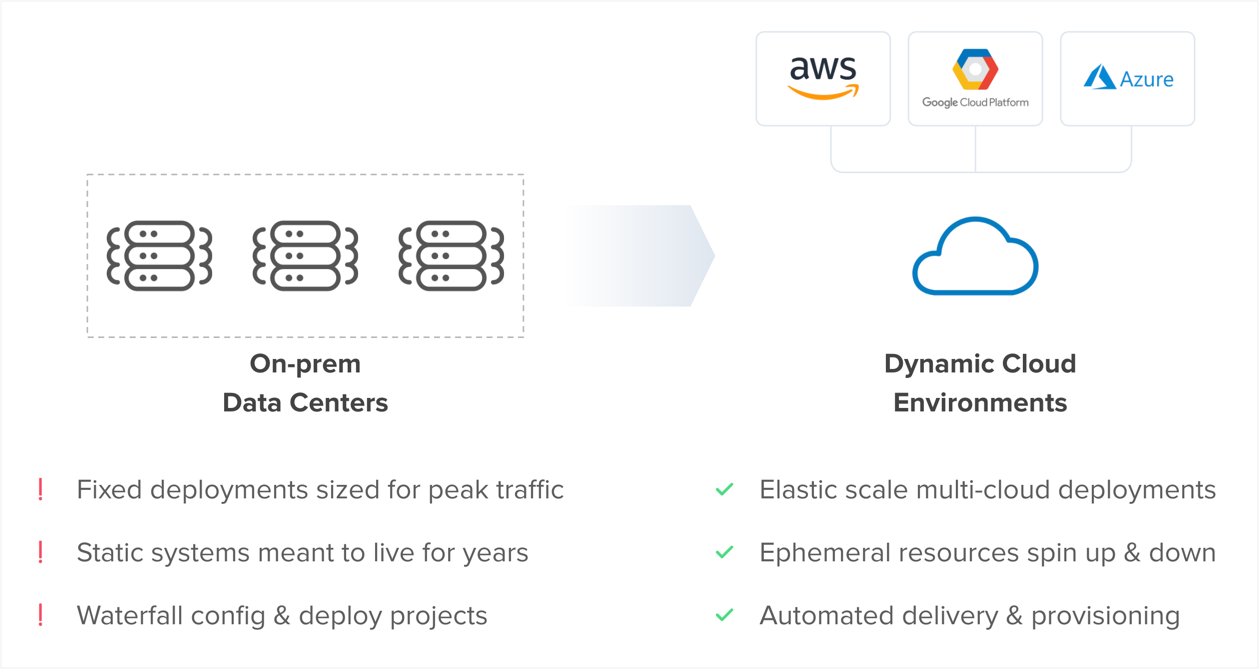
The demands for velocity at scale can only be realized by fully embracing the cloud, but it doesn’t come easily. With such a significant shift in environmental characteristics and behaviors, the underlying architecture must be able to adapt. Enter the Cloud Operating Model—a strategic framework for cloud adoption driven by a DevOps culture of automation that impacts people, process, and technology.
Fostering a culture of automation
It’s no accident that we lead with culture when discussing DevOps. Any agent of change needs to be blessed by the business for it to be successful, especially ones that span cross-functional teams. But you can’t simply declare a culture and call it a win; there needs to be alignment on shared goals, shared responsibilities, and shared accountability. Mature DevOps programs come from organizations that empower their teams because that’s when the culture can truly emerge.
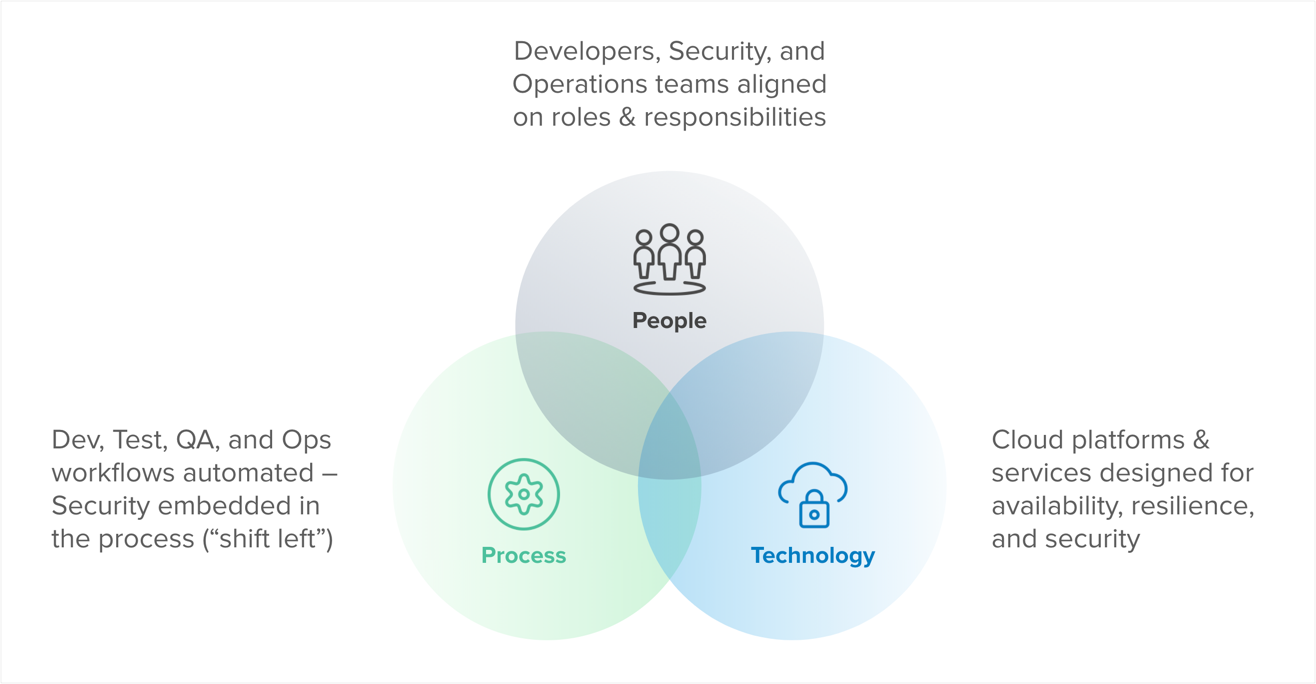
The people, process, and technology of a mature DevOps program are wrapped in automation, with security embedded right from the start. Self-organized teams deploy self-service tools to streamline the delivery and deployment of software, and the provisioning and configuration of infrastructure. A key reason cloud adoption requires a shift in the operating model is to remove any barriers from this automation in a secure manner. The traditional operating model is both a blocker to automation and a risk to security, which is bad for the business outcome of velocity.
Since speed can be quantified, the business leaders who are behind this change will expect results. And when speed is the outcome, the expectation for when it will happen is… fast. The key metrics that a DevOps program is measured on are related to software development and delivery, while the underlying operations and security functions act as the supporting cast (but hardly one that goes unnoticed).
The DevOps Research & Assessment (DORA) team, now a part of Google, found the following metrics most important for businesses to measure:
- Deployment frequency: How often does your organization deploy code to production or release it to end users? (high performers: between once per day and once per week)
- Lead time for changes: How long does it take to go from code committed to code successfully running in production? (high performers: between one day and one week)
- Time to restore service: How long does it generally take to restore service when a service incident or defect that impacts users occurs? (high performers: less than one day)
- Change failure rate: What percentage of changes to production or releases to users result in degraded service and subsequently require remediation? (high performers: 0-15%)
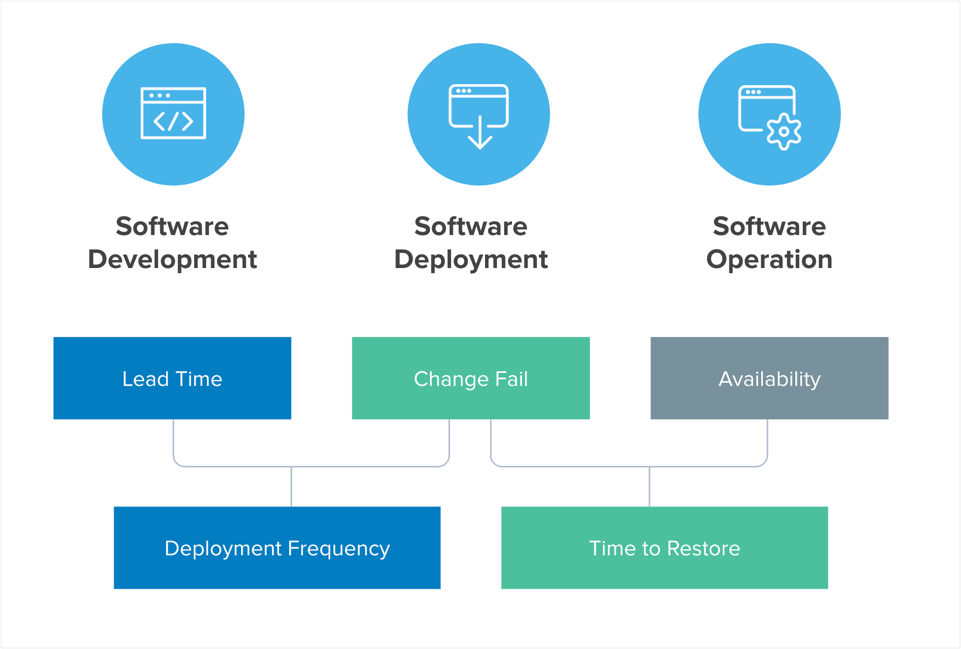
Source: DevOps Research Agency (DORA) State of DevOps Report 2019
With throughput and stability as the leading indicators for Dev performance, where does that leave the Ops side of the house? The DevOps function doesn’t end once software gets out the door; it takes a concerted effort to keep systems and applications healthy. There are three words that are top of mind for anyone responsible for operating cloud infrastructure—availability, resilience, and security. While these attributes have traditionally been counter to velocity given their protective nature, organizations with mature DevOps programs see them going hand-in-hand. Highly available systems better enable throughput, and resilient systems better enable stability.
Popularized by Google, the Site Reliability Engineering (SRE) role complements DevOps programs by taking ownership of the most critical metric of them all—uptime. Any company that delivers software as a service places their reputation on the line with their Service Level Agreement (SLA); we do at Okta with our 99.99% uptime SLA (that’s very good, by the way).
As an engineering function, SREs are constantly monitoring and improving systems and processes to minimize two key metrics:
- Mean time to Acknowledge (MTTA): How long does it take to begin working on an issue once an alert has been triggered? (high performers: less than 5 minutes)
- Mean time to Resolve (MTTR): How long does it take to resolve an outage and restore service to customers? (high performers: less than 1 hour)
The dynamic nature of the cloud with the constant drive for velocity makes this a hard job. Companies with mature DevOps programs tie SRE metrics back to the business—after all, uptime is a competitive advantage. The core engineering work of an SRE team is to build observability throughout the entire tech stack, and throughout every automated process. The more proactive you can be with potential bottlenecks, barriers, and breakers, the better.
Stitching it together
A fully automated software development, delivery, and deployment program doesn’t just happen overnight. Unless your business started yesterday, you’ll have technical debt to modernize and processes to streamline. DevOps is the unity of software development and infrastructure operations, but each carries their own independent roles and responsibilities. Maturity is defined by how efficiently it all comes together.
Inefficiencies exist when these functions are disjointed. Developers write code in isolation and then “throw it over the wall” for the operations teams to deploy. Aside from having varied definitions of done, this invariably leads to finger pointing when things go wrong. The famous, “it worked on my machine” tagline originates from this occurrence.
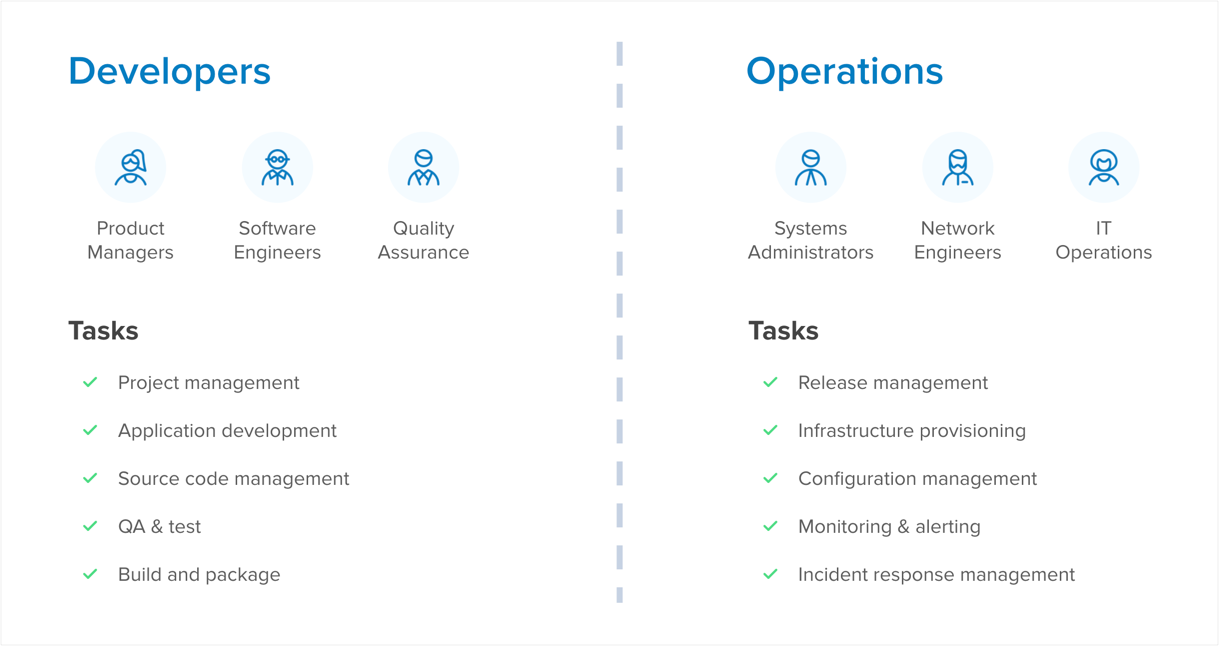
The rise of collaboration tools and the advent of virtualization technologies in the cloud have helped bridge this gap. With Virtual Machines and Containers, local runtime environments can closely mirror production environments. Software development and delivery processes flow through event-driven actions connected to the source control, most commonly Git. The various checkpoints along the way of these Continuous Integration and Continuous Deployment (CI/CD) pipelines enable better collaboration (and less finger pointing).
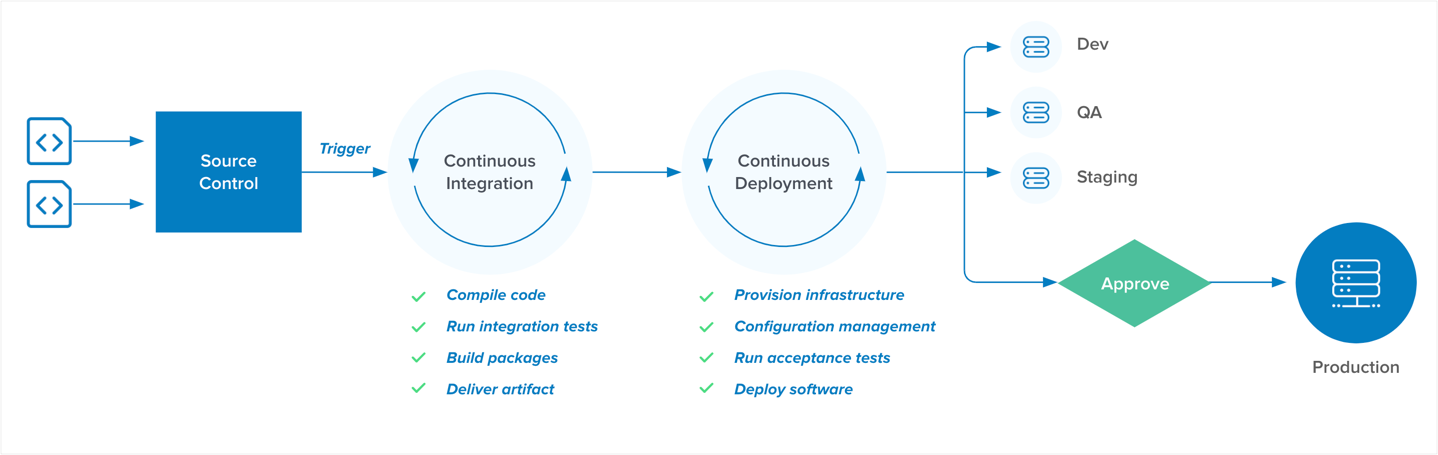
While the image above is a significant improvement compared to the legacy approach, there is still much to be desired. Development and Operations teams may still be disconnected, and the checkpoints may still contain heavyweight, manual processes. The “holy grail” state is to fully automate everything in a continuous cycle. What the business really wants is for developers to only be writing code, and for operations to only be optimizing for performance. Sounds like a dream.
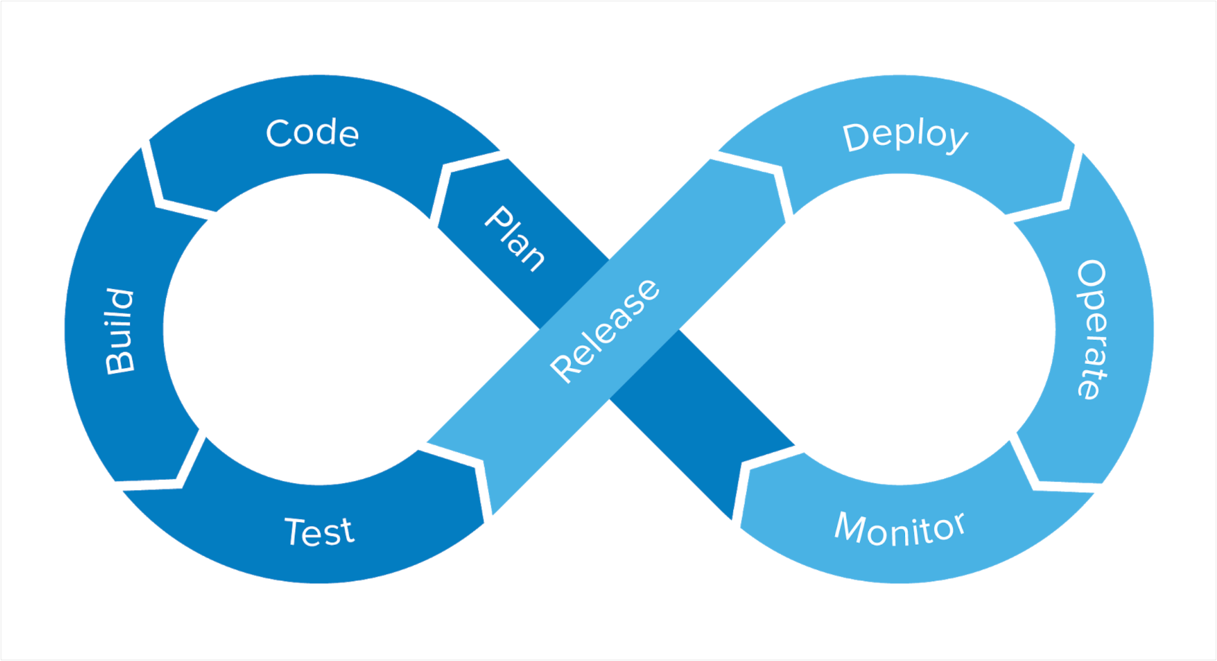
As with any ideal state, reality quickly kicks in, and this view of a continuous cycle of automation and collaboration may seem out of reach… and dangerous. But there’s nothing wrong with striving for the “holy grail” if you take the right incremental steps to get there and proceed with caution, rather than blindly reaching for the end state without consideration. In other words—Indiana Jones would make a great DevOps leader.
The balance between productivity and security
In the follow up posts in this series, we will discuss what this journey looks like in detail. I’ll close this first post with this—taking things in stride generally means approaching initiatives and challenges with a balanced mindset. Adapting the Cloud Operating Model as we’ve just discussed means balancing productivity and security. Or as I like to say, “Move Fast Without Breaking Things.” There are generally two perspectives with regards to productivity and security:
- Productivity without compromising security is the dev-centric perspective, taking great care that the automation being built factors in security considerations before deploying live in production.
- Security without impacting productivity is the ops-centric perspective, taking great care that the policies and procedures required to meet compliance guidelines don’t get in the way of the automation that is built.

These perspectives are really two sides of the same coin—enabling secure velocity at scale. When all the functions of DevOps are aligned in this way, the culture of automation really begins to take form, delivering the necessary continuous innovation back to the business for the win.
In our next post in this series, we will discuss the Sec in DevSecOps, and the critical role identity plays in this Cloud Operating Model. To learn more about the Cloud Operating Model and DevOps, check out the following resources:
