




What is the Snowpipe Streaming API
The Snowpipe Streaming API is a new Snowflake innovation that exposes a streaming API that can be used to connect and write directly to a Snowflake database using your own managed application. This prompts low-latency loads of streaming data rows using the Snowflake Ingest SDK and your own managed application code and removes the requirement of storing files in a stage compared to other approaches like Snowpipe. As Snowflake claims, this solution is scalable and reliable and can effortlessly ingest upwards of 1GB/s throughput.
Why use the Snowpipe Streaming API
An important use case for Okta is providing reports to help customers understand their Okta deployment and usage. These reports are available to the customers in our administrative console, and the data source that populates them is a Snowflake database. Our internal service, Data Ingestion Service, moves Okta usage data from Amazon Kinesis to a Snowflake database.
In the previous implementation of Data Ingestion Service, Okta used the Flink JDBC connector. To support real-time event data ingestion, we required a dedicated warehouse to be always active on each Okta cell and used in a low capacity. As a result, this data ingestion process consumed a lot of Snowflake credits.
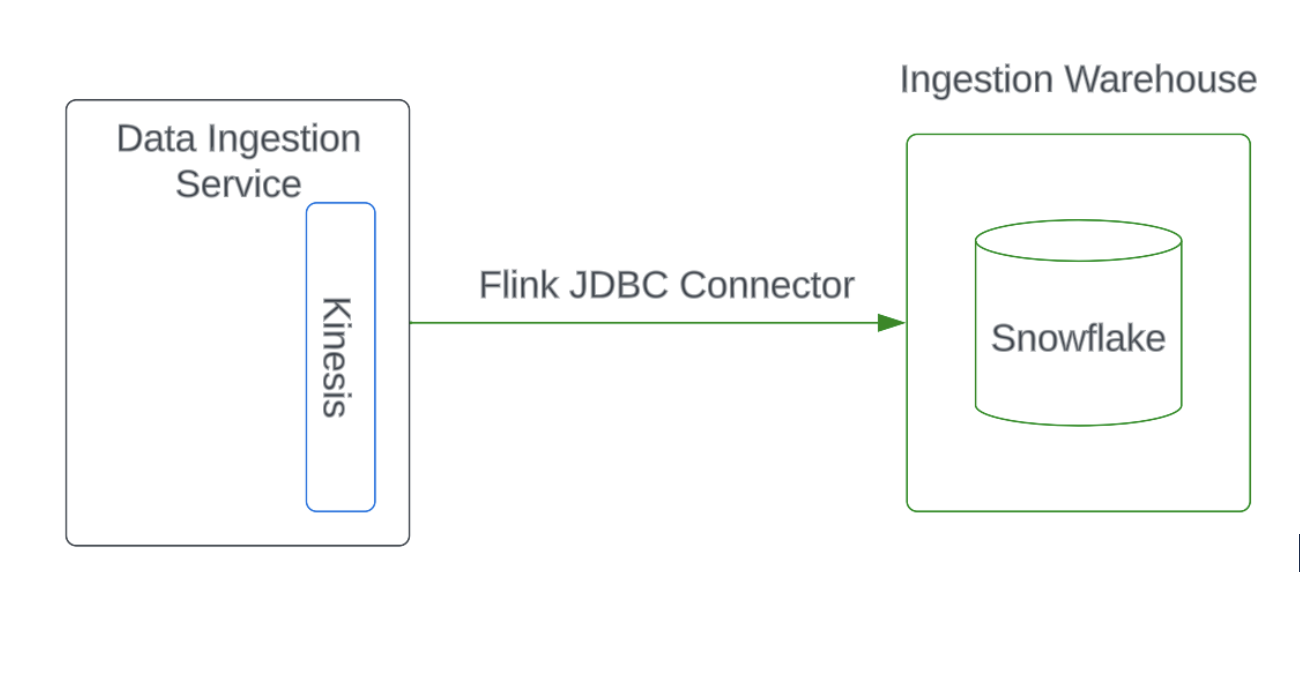
Because of a company-wide cost-saving plan, we needed a new, efficient ingestion solution that would lower human toil through automatic scaling based on load instead of human operator scaling, which would be necessary with a traditional warehouse. Then the Snowpipe Streaming API was brought to the table. Luckily, the Snowpipe Streaming API is a server-less service that does not require an active warehouse for data ingestion and automatically scales the load by itself with its backend Snowpipe implementation. It sounded like a great fit for our business case to provide a high and more efficient data ingestion solution.
Implementation
In the existing open sources, the Snowpipe Streaming API only has available sample codes to use with Kafka, but no libraries can be used for Kinesis to use Snowpipe Streaming API, like the Flink JDBC Connector. Therefore, in our business case, we had to write this part, called Snowpipe Streaming API Connector, from scratch.
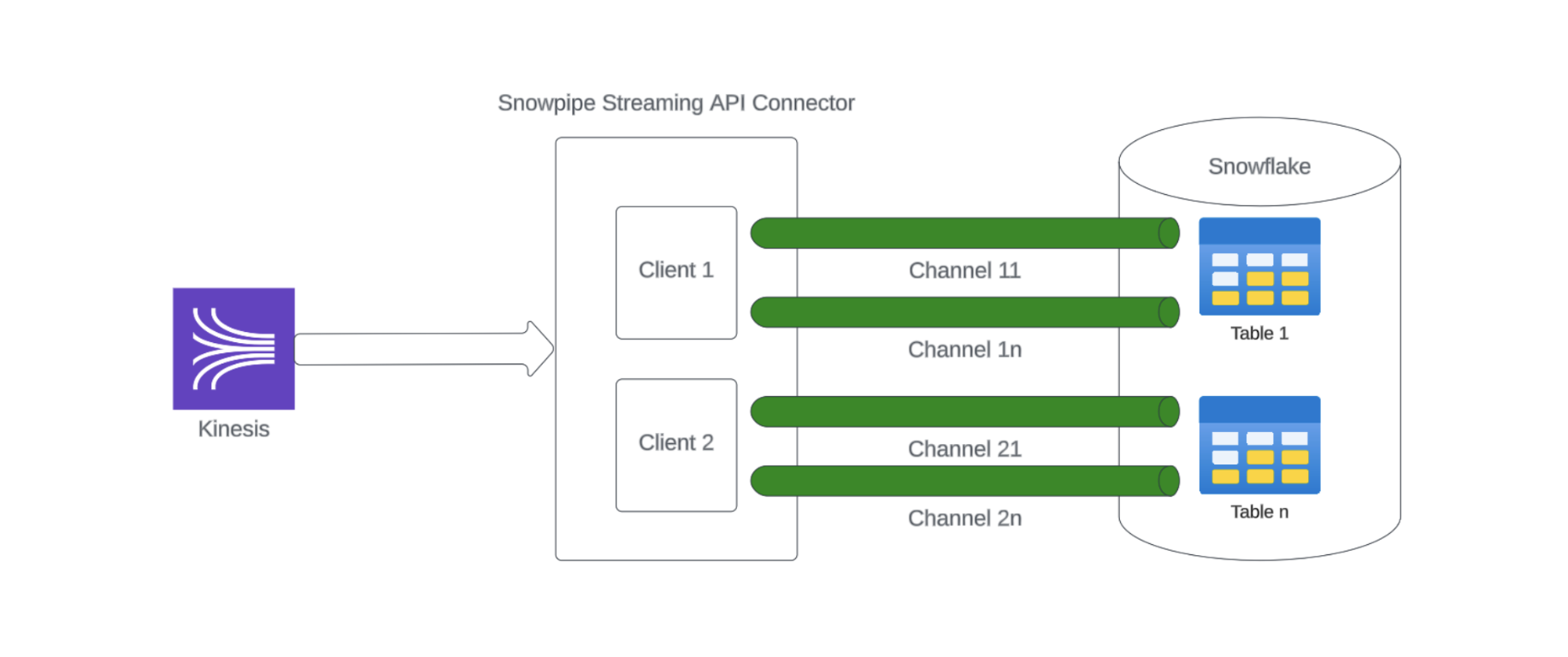
There are two major responsibilities for Snowpipe Streaming API Connector.
- Get the input data from Kinesis.
- Convert the input data to the desired data format and then move them to Snowflake with batch through Snowpipe Streaming APIs.
After Snowpipe Streaming API Connector is implemented, our Data Ingestion Service uses it to connect to the Snowflake tables.
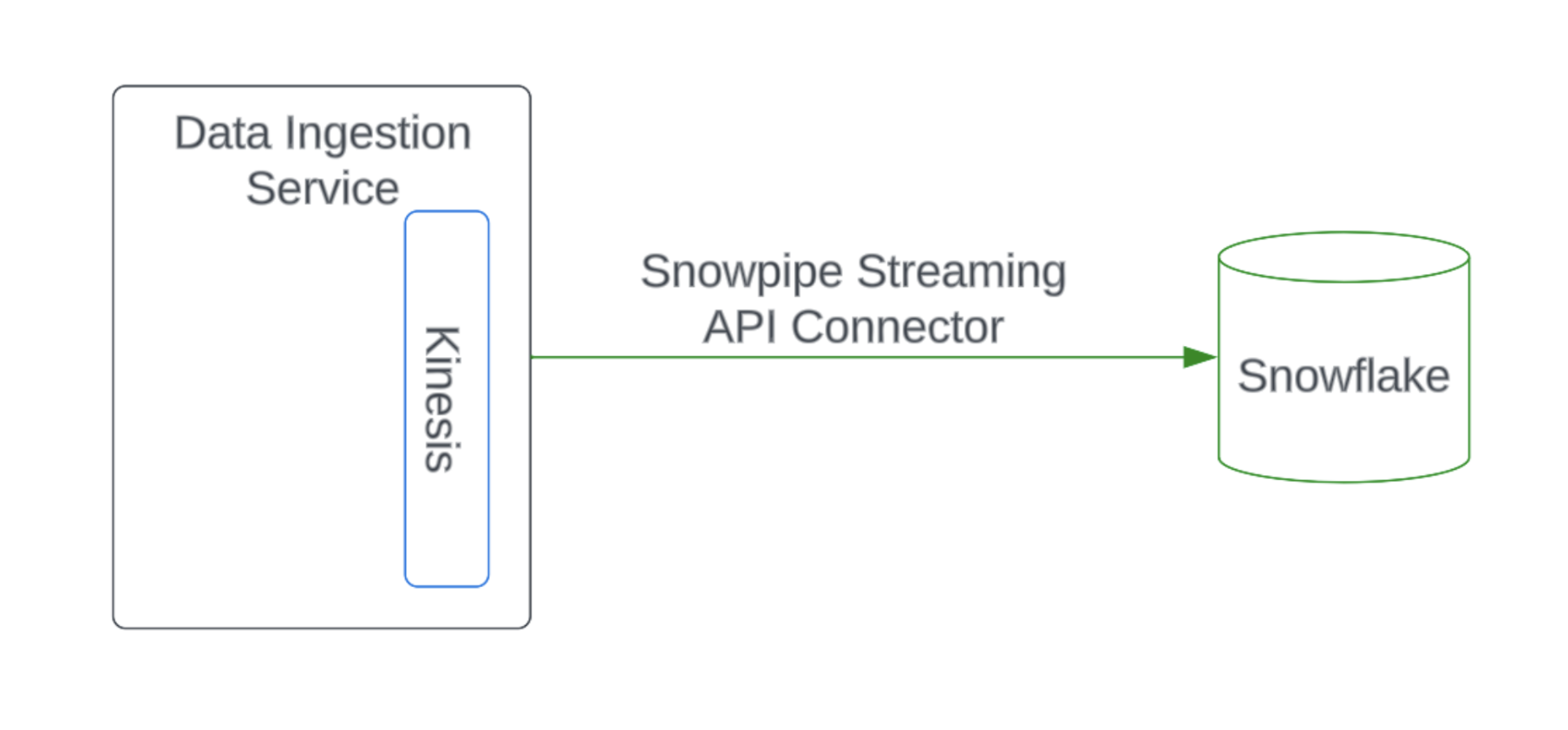
Lessons learned
We learned two lessons during the implementations.
- To serve our Federal customers, every Okta deployment must adhere to FedRAMP authorization standards. This includes using FIPS-validated libraries. To do this, we had to exclude the snowflake-jdbc jar file from the Snowpipe Streaming API package while adding the snowflake-jdbc-fips jar file with the suitable tunings.
- A channel created per table, which is a logical, named streaming connection to Snowflake for loading data into a table, can’t be released or deleted even after the service closes the channel. The channel limit per table is 10K. Once it reaches this limit, it will fail to use the Snowpipe Streaming API anymore. In our initial implementation, we assumed that the channel would be deleted or released once the service closes the client or channel, and then we used the random strings as the channel names. Unfortunately, when we hit the restarting loop of our ingestion service, it used all the channels within hours and failed to perform data ingestion anymore. Then, we contacted Snowflake support, who pointed out that a channel would be deleted only after being inactive for more than 90 days. So, in your coding, please try to re-use a channel as much as possible while never using random strings to assign the channel name. If you accidentally reach this limit, you have to contact Snowflake support to raise the limit temporarily.
Results
After deploying the Snowflake Streaming API to our environments, we observed:
- More savings on low-traffic environments: In our low-traffic environments (deployments), it saves us around 50% compared to the previous; in high-traffic environments, it saves us around 20%-30%. For example, one week before the change, we used 222.52 credits (including costs like ingestion, reclusting, and report queries) for one Snowflake account, which was underutilized. One week after we deployed the Snowpipe Streaming API, we used 109.5 credits for the same Snowflake account. We also found that, in this Snowflake account, the credit consumed by Snowpipe Streaming API is too small to be ignored.
- CPU usage of our ingestion service has significantly dropped from 90-100% to 20%-50%. Before the change, the dedicated JDBC connections had to be always active to move data into the Snowflake tables, and each connection had to build a separate connection with Snowflake. However, the Snowpipe Streaming API only opens one client per table and leverages the channels within the client to do the data ingestion, meaning it efficiently manages CPU usage by taking advantage of Snowpipe in its Snowflake side.
- Heap usage of our ingestion service has dropped around 5-10%. This likely means the Snowpipe Streaming API did some data compression optimizations when moving data from our service to Snowflake.
Overall, the Snowflake Streaming API was much more efficient than the Flink JDBC connector. There were specific things we had to do that weren’t turnkey (e.g. FIPS and Snowpipe Streaming API Connector). We’ve been running the Snowflake Streaming API successfully for over two months in our production environments and are pleased with the experience compared to the previous solution.
Have questions about this blog post? Reach out to us at eng_blogs@okta.com.
Explore more insightful Engineering Blogs from Okta to expand your knowledge.
Ready to join our passionate team of exceptional engineers? Visit our career page.
Unlock the potential of modern and sophisticated identity management for your organization. Contact Sales for more information.


