





International revenue share fraud (IRSF), also known as toll fraud, is a type of fraud where fraudsters artificially generate a high volume of international calls/SMS on expensive routes. Here’s how it works.
- Fraudsters exploit Okta’s authentication flow and make expensive phone calls and/or texts as part of the MFA flow where phone/text is used as one of the factors
- Fraudsters tend to make calls to what are known as premium rate numbers or other high-cost destinations to maximize the profit
- Fraudsters take a cut of the revenue generated from these calls
Due to the high costs associated with long-range international telephony transactions, toll fraud can bear a significant financial impact on the business. However, for many of our customers, SMS and voice are part of a crucial MFA flow that must remain reliable and uninterrupted. In this article, we will share how we protect our systems from toll fraud while providing reliable telephony service to our customers, and how we improved our toll fraud mitigation by 20% by introducing machine-learning-based detection.
System requirements
Okta is a mission-critical service. Billions of authentications are processed through Okta’s network. As such, it is crucial to define a set of requirements while designing the anti-toll-fraud system.
- No disruption: Customers rely on Okta to access applications and resources they need for day-to-day operations. No disruption is a critical requirement for us and we need to ensure that authorized users are granted access to their accounts and their accounts remain uninterrupted.
- Low latency: Our rate enforcement decisions must be performed with low latency. User experience is another critical requirement, and our decision must be fast to determine whether to allow or block incoming requests.
- Flexibility: Our reaction must be fast and flexible so detections and enforcements are tunable for different traffic patterns and organizations.
The above requirements have motivated us to build a system that consists of a few modular components. Now we will review them in the following sections.
Rate limit scopes
Rate limit scopes are crucial components in the anti-toll-fraud system, they are separate from regular endpoint-specific rate limits, and they differ in two ways.
Rate limits are narrowly-scoped
Anti-toll-fraud rate limits are scoped on specific parameters related to the transaction. For example, instead of having per-endpoint thresholds, anti-toll-fraud rate limits may have separate rate limit buckets for different transaction intents (e.g., password reset), geographic subregions, IP ranges, similar phone numbers, and so on. Unlike legitimate customer traffic, fraudulent traffic is often more likely to originate from a specific phone number range or be less geographically distributed; therefore, narrowly scoped rate limits allow us to target specific parameters while leaving legitimate traffic channels unaffected.
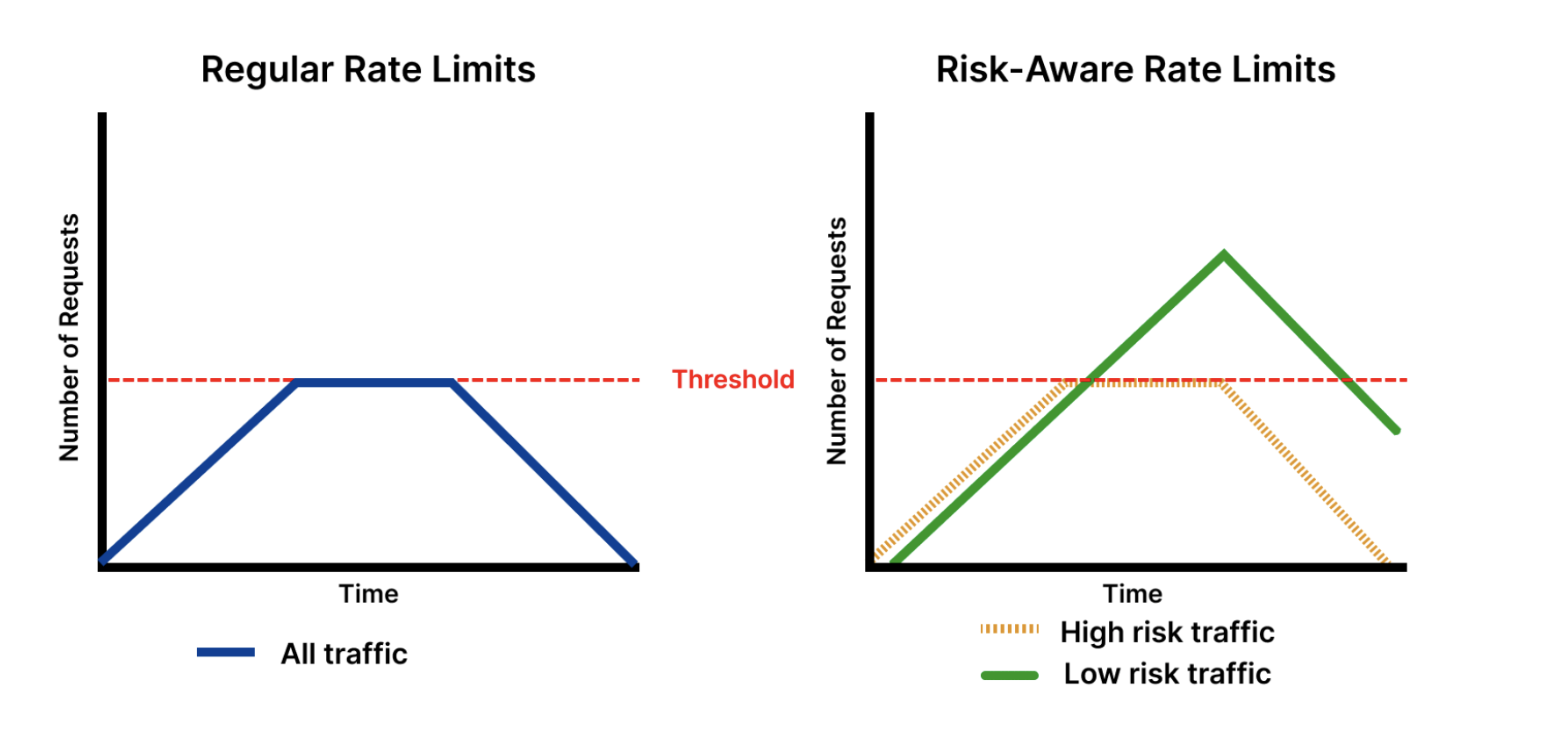
Rate limits are risk-aware
Anti-toll-fraud rate limits, in addition to being scoped on specific parameters, distinguish transactions based on different categories of risk determined by our system. This means that two transactions over the same set of parameters (e.g., password reset transactions originating from the same IP address), may not be subject to the same rate limit threshold. Our system first determines a set of risk markers (indicators that the transaction might be fraudulent) that apply to a certain transaction, then the system evaluates the transaction against rate limits that are set against that risk category. These risk markers may be determined by the country of registration of the phone number, various heuristics-based formulae, or risk scores produced by machine learning models described in later sections.
This approach has two advantages. First, traffic that is considered low risk isn't subject to tight rate limits, so we can set lower thresholds without affecting legitimate customer traffic. Second, this system enables us to utilize toll fraud detection mechanisms that may generate occasional false positives, as rate limits don’t block all transactions outright.
Detection of risk markers
Our goal is to determine if a transaction is risky or not in the context of a toll fraud attack. The transactions here include both SMS and voice traffic. Once a transaction is determined as risky, the transaction becomes a risk marker and associated parameters (e.g., IP, phone prefix, country) become the candidates for facing potential rate limits. The anti-toll-fraud system we designed consists of three complementary detection mechanisms: the heuristic engine, the unsupervised ML engine, and the supervised ML engine. The supervised ML capabilities will be added as needed. We’ll cover it in a separate blog post.
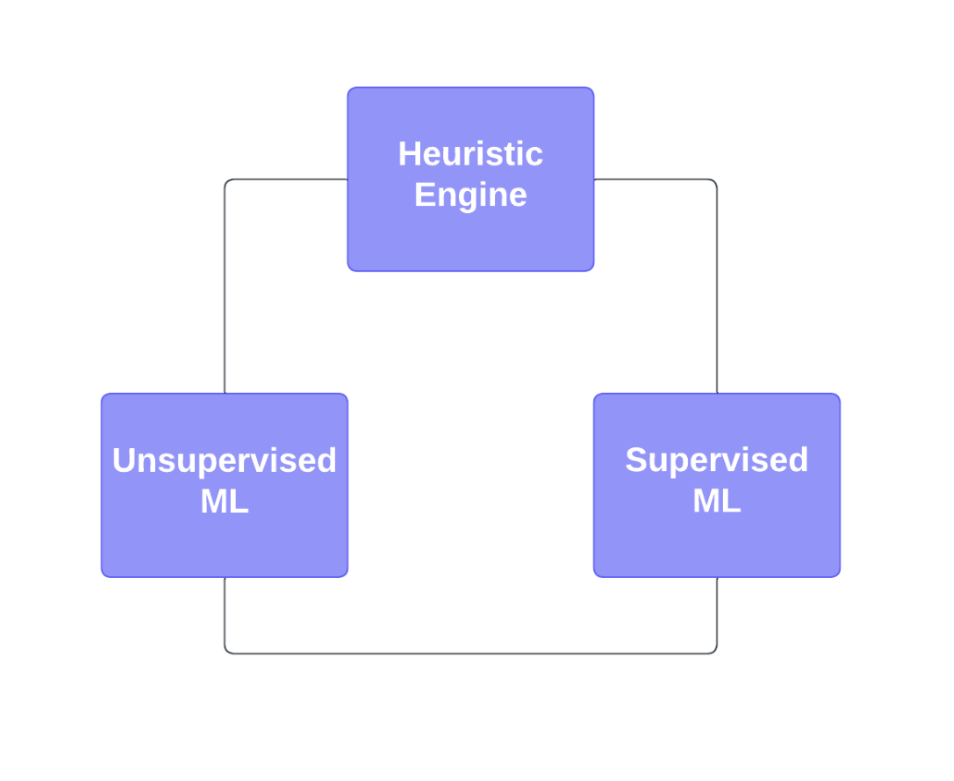
Heuristic engine
Each SMS or voice request is immediately evaluated against a set of heuristics. Transactions that fit a certain set of heuristics are made subject to rate limits described in the previous section. They generally depend on end-user parameters such as a client's IP address or phone number.
Unsupervised machine learning
The unsupervised machine learning engine is based on the isolation forest algorithm, a tree-based algorithm that works by recursively partitioning the dataset into smaller subsets. The algorithm uses the depth of the trees needed to isolate an instance as a measure of its anomaly score. The intuition behind the algorithm is that anomalies are rare instances that can be isolated with fewer splits than normal instances. The algorithm works by randomly selecting a feature and a split point to divide the data at each step. This process is repeated recursively until all instances have been isolated. The anomaly score of an instance is calculated as the average path length of the trees that isolate it. Instances with a low average path length are considered anomalies, while instances with high average path lengths are considered normal.
We have selected this algorithm in the unsupervised ML engine for a few reasons. This approach is highly efficient and effective in detecting anomalies. It does not require a pre-existing model of normal behavior. It also can handle high-dimensional datasets with ease.
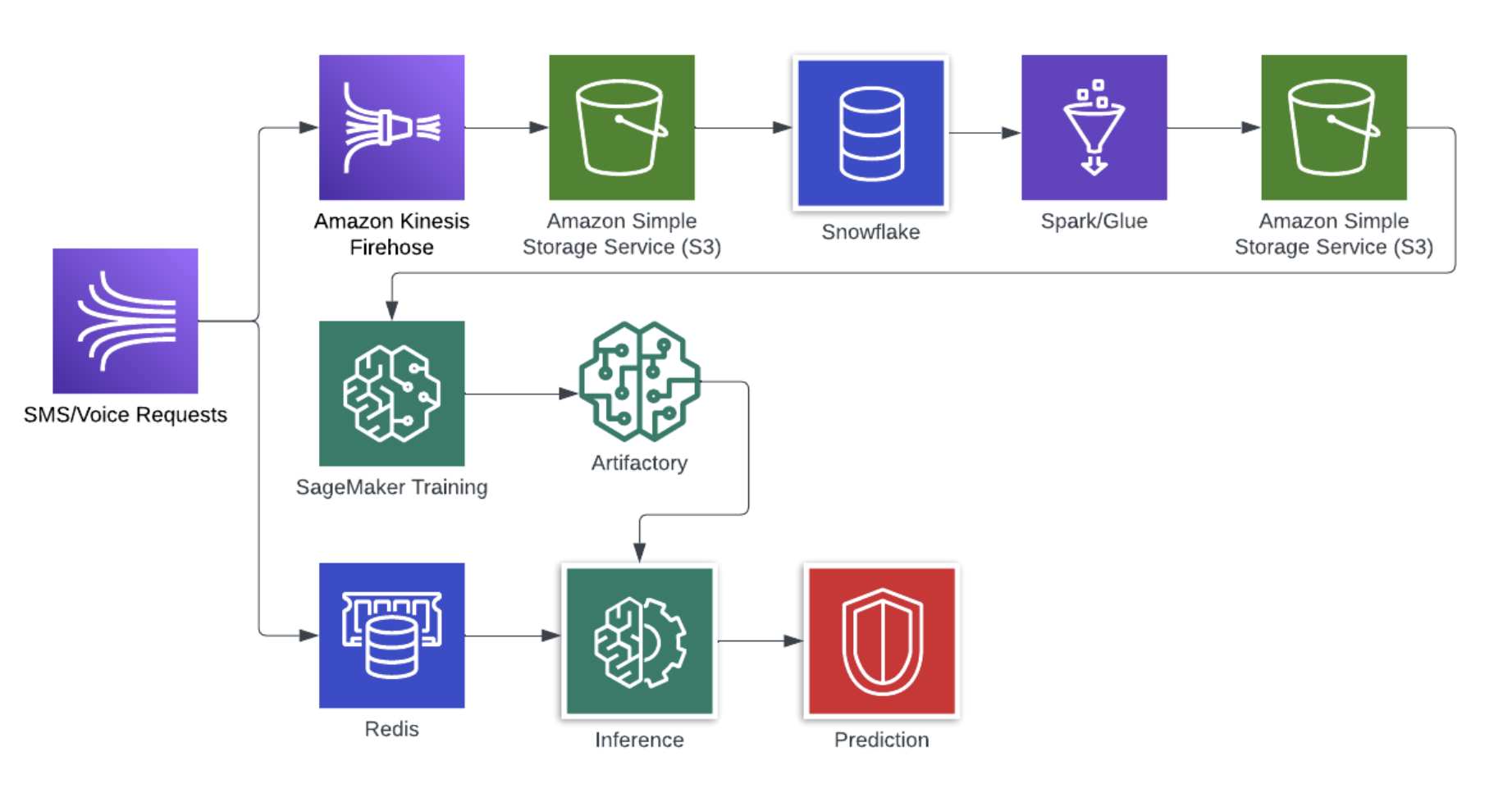
The above figure shows the architecture of the unsupervised ML engine. Overall, the architecture consists of the Extract, Transform, and Load (ETL) pipeline; training pipeline; and inference pipeline. Our events data lands in AWS S3 storage through Amazon Kinesis Firehose. The data then becomes available in Snowflake for analysis. The feature (an input to the ML model) extraction and generation are completed through Spark/Glue jobs via a Snowflake connector. The extracted features are stored in AWS S3 as well. Finally, Amazon Sagemaker is used for training the algorithm. The model artifact generated from the training pipeline is then used for predictions.
Every voice or SMS request is evaluated live against the toll-fraud model. This means when a user requests an OTP message, we need to compute all the features applicable to that request and run inference on the model before sending out the message. We can achieve both live evaluation and fast performance by using Redis cache.
After applicable features are computed, the model inference is run, resulting in the risk score. Then the transaction may be assigned a risk marker if the score is above a certain threshold, which may subject the transaction to a set of predetermined rate limits.
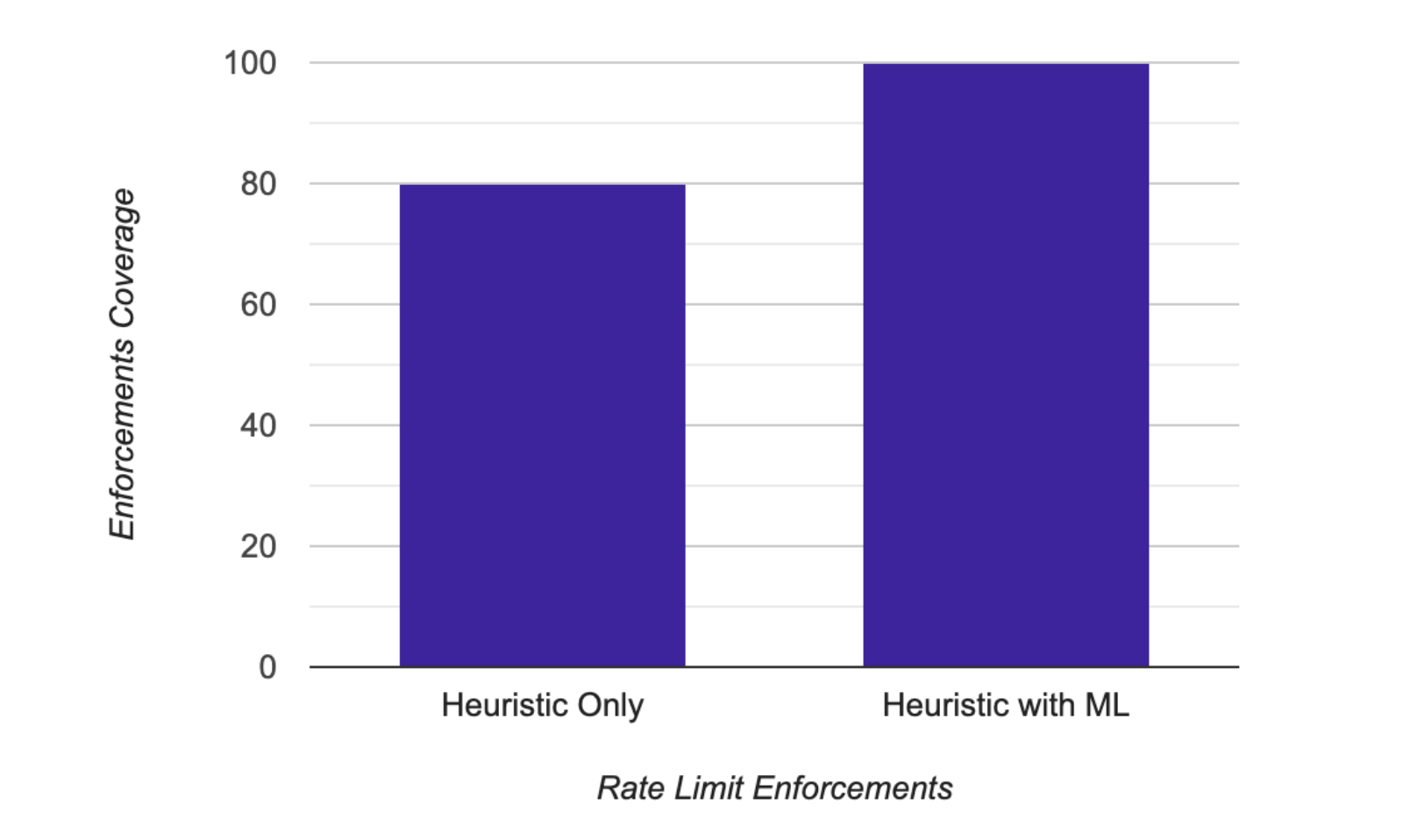
This model has detected thousands of toll fraud attacks every month in production. The above bar chart shows the current distribution of rate limit enforcements as determined by the heuristic engine only and along with the unsupervised ML engine. Quantitatively, after introducing this model, we are rate limiting 20% additional traffic on top of those by the heuristic engine without increasing false positives. In other words, these 20% fraudulent transactions would not have been captured by the heuristic engine.
It is also worth noting that the rate limit enforcement on toll fraud traffic has deterrent effects, meaning fraudsters exhaust their resources, realize a particular campaign is not profitable for them, and decide to give up or attack somewhere else.
In one specific example, a large customer with an international customer base was targeted by a toll fraud attack. The attack was globally distributed and not sufficiently mitigated by existing heuristic-based rate limits. By turning on ML-based rate limits, we were able to force the fraudsters to give up on the attack. This saved us thousands of dollars by deterring fraudsters from attacking just this one customer.
We are not stopping here; we have developed a supervised ML model to further boost our toll-fraud detection capabilities within the anti-toll-fraud system.
Catering to individual customers
We employ a series of alerts triggered either by spikes in unusual traffic or repeated rate limit violations. These alerts allow our team to adjust rate limits for individual organizations as needed, depending on their traffic. For example, we may proactively loosen rate limits to specific high-risk countries for organizations that have high volumes of legitimate traffic to those destinations. In other cases, we may tighten existing thresholds to stop fraudulent actors that tried to remain under default rate limit thresholds.
Have questions about toll fraud and how to mitigate it? Reach out to us at eng-blogs@okta.com.
Explore more insightful Engineering Blogs from Okta to expand your knowledge.
Ready to join our passionate team of exceptional engineers? Visit our career page.
Unlock the potential of modern and sophisticated Identity management for your organization. Contact Sales for more information.


