



Okta’s mission is to allow everyone to safely use any technology. Okta handles billions of authentications a month, helping users securely access their favorite applications. Okta also blocks billions of malicious requests every month, protecting our customers’ Identities from attacks.
Okta’s platform has a multi-layered defense strategy to protect Identities. A key aspect of such a defense-in-depth strategy is risk. Okta’s platform computes risk at various levels and is a critical component of our defensive strategy. We strongly recommend that customers configure risk-based policies to prompt MFA for high-risk logins.
Identity Risk scoring at Okta today is powered by what you’d expect from a mature security company - our ML stack. We take every relevant authentication or identity-related event, turn it into a structured record (IP, device, user agent, country, and so on), manually engineer a large set of features, and feed those into a machine learning model.
This eventually powers identity risk scoring in products such as Okta AI's Identity Threat Protection, continuously evaluating user and session risk using network, device, and other signals.
However, with the advent of LLMs, we’ve begun experimenting with new approaches and asking how we can leverage them for adaptive risk scoring. After all, security logs are fundamentally sequences of structured text: event types, IP addresses, user agents, org IDs, geo signals, and more. Instead of compressing all of this into a fixed feature vector, can we treat the logs as a native text stream and use an LLM to perform identity risk scoring directly from system log data?
This post describes one such experiment: an LLM-based adaptive risk scoring that learns the sequential patterns and emits anomaly scores using a probabilistic objective.
Traditional ML Scoring
A sign-on flow doesn’t produce just one event; it produces a timeline of related events. For a single identity, a slice of that history might look like this (simplified):
t₁: event_type=user.session.start …
t₂: event_type=user.authentication.sso country=Germany
ip_address=145.224.xxx.xxx user_agent_raw=SFDC-Callout/64.0
browser=UNKNOWN os=Unknown device=Unknown as_org=amazon.com inc.
request_uri=/oauth2/.../v1/token …
t₃: event_type=inline_hook.response.processed …
t₄: event_type=user.authentication.sso …
t₅: event_type=user.session.end …
Over time, the user’s history becomes a sequence:
[e1, e2, …, e(n−1), en]
In the traditional pipeline, we almost never feed these raw events directly into a model. Instead, we collapse the sequence into engineered features computed over windows of time or history, for example:
- “Is this IP new for this user?”
- “Is this ASN new for this org?”
- “Have we seen similar user agents in the past?”
- …and more
The incoming event becomes a numerical feature vector relative to the User’s past history, say:
features(event) → x ∈ ℝᵈ
A model learns a mapping:
risk = f(x)
where f is typically a machine learning model.
The catch is that the history of events for that identity is compressed into a handful of counters and flags (aka features). The model doesn’t really “see” the story of the identity over time; it sees a snapshot plus a few aggregated numbers. The sequential aspect is also lost in that compression.
Why LLM?
LLMs shine at exactly what security logs represent: sequences of semi-structured text. Instead of looking at one login in isolation, an LLM can consume a timeline of all the important events for a user or agent:
“This identity usually authenticates from Germany, via an API client, during business hours, with a very specific user agent string…”
From this, the model can implicitly learn:
- What “normal” looks like for each identity
- Which combinations of fields tend to co-occur
- When a new event deviates from that baseline in subtle ways
- Whether a new event is even anomaly at a global level
There are three big advantages:
- Sequences
LLMs can read multiple events in sequence, not just a single snapshot. They treat the entire sequence as a story and judge whether the next chapter makes sense. - Less manual feature engineering
Instead of designing hundreds of features by hand, we let the model learn patterns directly from raw event text. This saves engineering time.
- Better generalization to new patterns
Because the model sees full sequences, it can flag surprising combinations it’s never seen for that identity - even if we didn’t build a feature for that specific pattern.
This means, instead of flattening everything into a single snapshot, we can feed a fine-tuned LLM model the entire sequence of events for a user or agent and ask: Given how this identity usually behaves, does this next event look normal or weird?
At a high level, there are two key parts in the system:
- Teach an LLM to predict the next event given the User’s historical profile and preceding events and tokens
- Use the model’s surprise as an anomaly/risk score
We will discuss them next.
Fine-Tuning LLM
Fine-tuning an LLM is essentially a way of teaching it the patterns we see every day in Okta’s identity data. The experimental setup we’re using consists of three stages: build a historical context or profile for the user, condition the LLM on that profile, and train it to predict the next event.
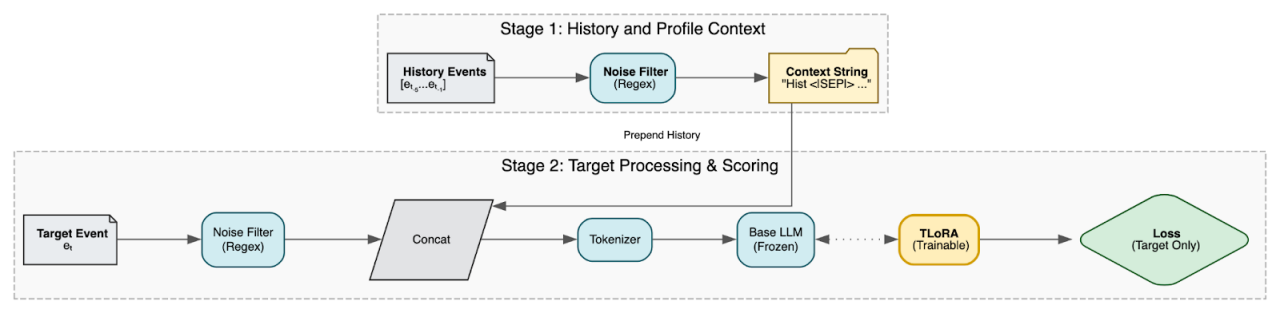
1. Turning event history into a profile
For a given identity, we start with a sequence of past events:
history = [e₁, e₂, …, eₙ₋₁],
current event to score = eₙ.
Instead of converting these into abstract vectors, we treat the raw text sequence as the profile. However, raw logs contain high-entropy noise (random transaction IDs, hashes, nonces) that confuses the model. We pass each event through a Noise Filter that replaces these random values with static placeholders (e.g., <ID>).
These cleaned text sequences are used to create a profile p. This captures “what this identity typically looks like” across its recent history - countries, ASNs, user agents, and flow patterns - in a format the LLM can natively read.
2. Conditioning a language model on the profile
We then take a GPT-style language model and modify the input so that it doesn’t just see the event eₙ, but also the historical context p.
We do this via contextual prompting. We concatenate the historical events (profile) with the target event, separating them with a special token. So instead of the model seeing just the target:
[tokens(eₙ)]
It sees the full behavioral narrative:
[tokens(e₁), , tokens(e₂), ... , tokens(eₙ)]
This forces the model to encode “here is the sequential behavior of this identity; predict the following tokens in that context.”
To make this efficient, we don’t retrain the entire language model. We freeze the base model and attach small low-rank adapter layers. We use an in-house–developed fine-tuning method called TLoRA. Only the adapters are trained, which keeps the footprint small.
3. Training objective
Training data comes from sequences of real event histories. For each sequence:
- We feed the full Profile + Target sequence into the model.
- We calculate the loss exclusively on the target event eₙ.
We train the model using a standard language modeling objective (Next Token Prediction): it assigns high probability to each token in the last event, given the user's specific history. The model is rewarded when it correctly anticipates the user's next action based on their past behavior and penalized when it is surprised.
Over many identities and sequences, the model learns a notion of “normal next event” conditioned on the user's specific profile p.
Risk Scoring based on Perplexity
Once the model is trained, we can turn its “surprise” into an anomaly score.

Summarizing, for a new incoming event:
- Retrieve the profile p from the identity’s recent past history.
- Feed the profile and the tokenized event into the model.
- Ask: how likely was each token of this event, given the profile and the preceding tokens?
This gives us a negative log-likelihood (NLL) per token and perplexity:
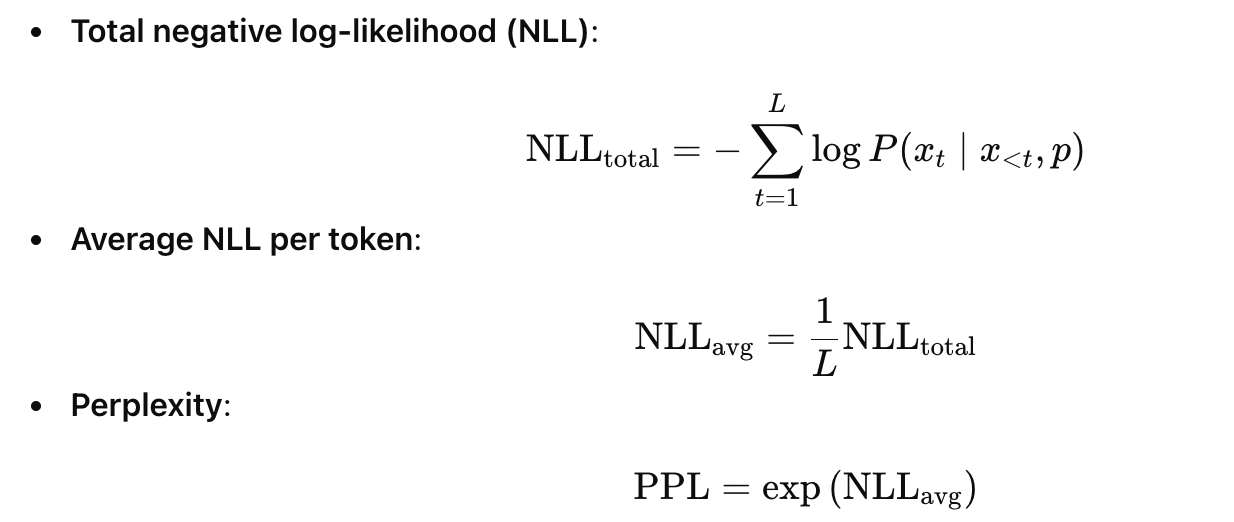
However, standard log lines contain significant static "boilerplate" text that dilutes the signal. Therefore, instead of a simple global average, we calculate Peak Perplexity. We isolate the Top-K most surprising tokens (i.e., the highest NLL values) in the target event, average only those, and then exponentiate. This ensures the score focuses on the information (e.g., Country, ISP, Device) rather than the structure.
Operationally, the risk score is derived from this perplexity:
- Low PPL → Low Risk: the event looks very typical for this identity.
- High PPL → High Risk: the event looks unusual, given everything the model has learned and inferred based on this identity’s history.
Because the model is conditioned on the per-identity profile, this is inherently adaptive.
Conceptual Example
To illustrate how this works in practice, let’s look at a real sequence processed by our model.
The model reads the event history like a narrative. It establishes a "profile" for the user based on their context - where they are, what device they use, and how they typically authenticate. It then evaluates the Target Event to see if it fits that narrative.
Below is a simplified trace of a user session. We have stripped out high-entropy noise (like IDs and hashes) to show exactly what the model focuses on. This is a simplified version.
1. The Context (Profile)
The model consumes these events first to understand the user's current state.
[T-3] Session Start xevent_type=user.session.start | country=United
[T-2] MFA Verification event_type=user.authentication.verify |
country=United States | os=Windows 10 | device=Computer |
result=SUCCESS
[T-1] Internal Auth event_type=security.internal.authentication |
country=United States | os=Windows 10 | device=Computer
2. The Anomaly (Target Event)
The user suddenly accesses the admin app, but the context has shifted drastically.
[T-0] Admin Access event_type=user.session.access_admin_app |
country=India | city=Chennai | os=Android | device=Mobile
How the Score is Calculated
When the model processes the Target Event, it calculates the probability of each token given the profile.
Based on the established context of "United States" and "Windows," the model strongly predicts that those tokens will appear again. When it encounters India and Android instead, the probability for those specific words drops to near zero. This contextual mismatch causes a massive spike in loss for those tokens, driving the Peak Perplexity score high enough to flag the anomaly.
By using Peak Perplexity, the LLM isolates the semantic contradiction: the user physically cannot travel from Kansas to Chennai instantaneously and switch devices mid-stream.
Looking Ahead
This LLM-based identity risk scoring is still in the experimental phase, but it gives us a concrete, mathematically grounded path forward:
- We move from hand-engineered feature vectors to profile-conditioned sequence models.
- We obtain a principled anomaly score using NLL and perplexity rather than ad hoc rule weights.
- We can integrate this anomaly score into existing risk pipelines as an additional signal, rather than replacing what works today.
Future work would focus on improving profile building, calibrating the perplexity-to-risk mapping, and possible extensions, such as generating natural-language explanations for why an event was deemed surprising.


